서론
최근 오픈 가중(open-weight) 모델 릴리스가 잦아지면서 주요 트렌드를 파악하기 어려운 분들을 위해 2026년 1월에서 2월 사이에 발표된 10개의 주요 모델을 정리해 드립니다.
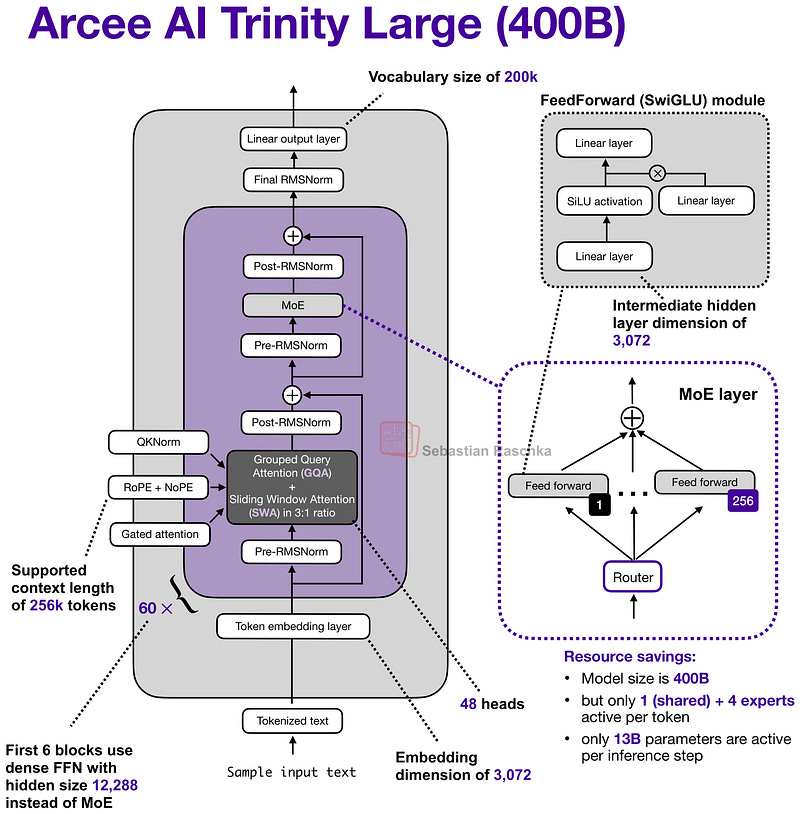
1. Arcee AI의 Trinity Large
발표일: 2026년 1월 27일
Trinity Large는 400B 파라미터의 Mixture-of-Experts(MoE) 모델로, 토큰당 13B 활성 파라미터를 사용합니다. 미국 신생사인 Arcee AI에서 공개했습니다.
주요 특징
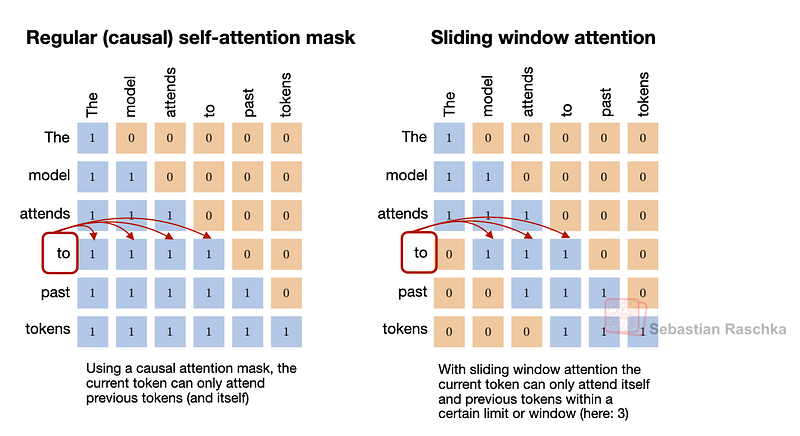
- Sliding Window Attention (SWA): Gemma 3, Olmo 3와 유사한 3:1 local:global 비율 사용
- QK-Norm: 훈련 안정화를 위한 키/쿼리 정규화
- NoPE (No Positional Embeddings): 글로벌 어텐션 레이어에서 위치 임베딩 제거
- Gated Attention: Attention Sinks 감소 및 긴 시퀀스 일반화 개선
2. Moonshot AI의 Kimi K2.5
발표일: 2026년 1월 27일
Kimi K2.5는 1조 파라미터의 모델로, 당시 오픈 가중 모델 중 최고 성능을 달성했습니다.
주요 특징
- DeepSeek V3 아키텍처 기반: DeepSeek V3의 확장 버전
- 멀티모달 지원: 시각 지원을 위한 네이티브 멀티모달 모델
- Early Fusion: 프리트레이닝 초기부터 비전 토큰을 텍스트 토큰과 함께 투입
3. StepFun의 Step 3.5 Flash
발표일: 2026년 2월 1일
Step 3.5 Flash는 196B 파라미터의 효율성 중심 모델로, 100 tokens/second의 높은 처리량을 자랑합니다.
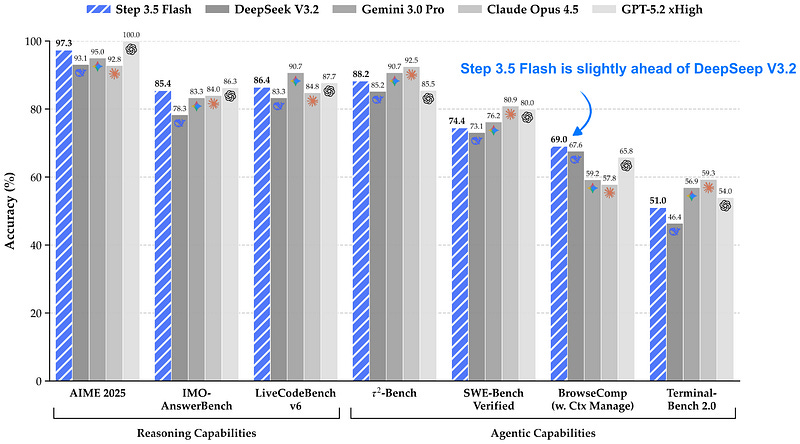
주요 특징
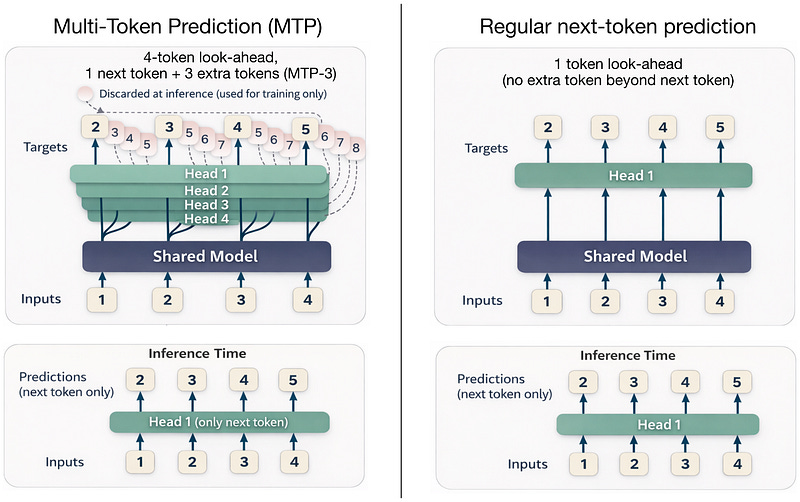
- Multi-Token Prediction (MTP): 훈련 및 추론 시 3개의 추가 토큰 예측 (MTP-3)
- Gated Attention: 훈련 안정성 및 긴 시퀀스 일반화 개선
- 높은 처리량: 128k 컨텍스트에서 100 토큰/초
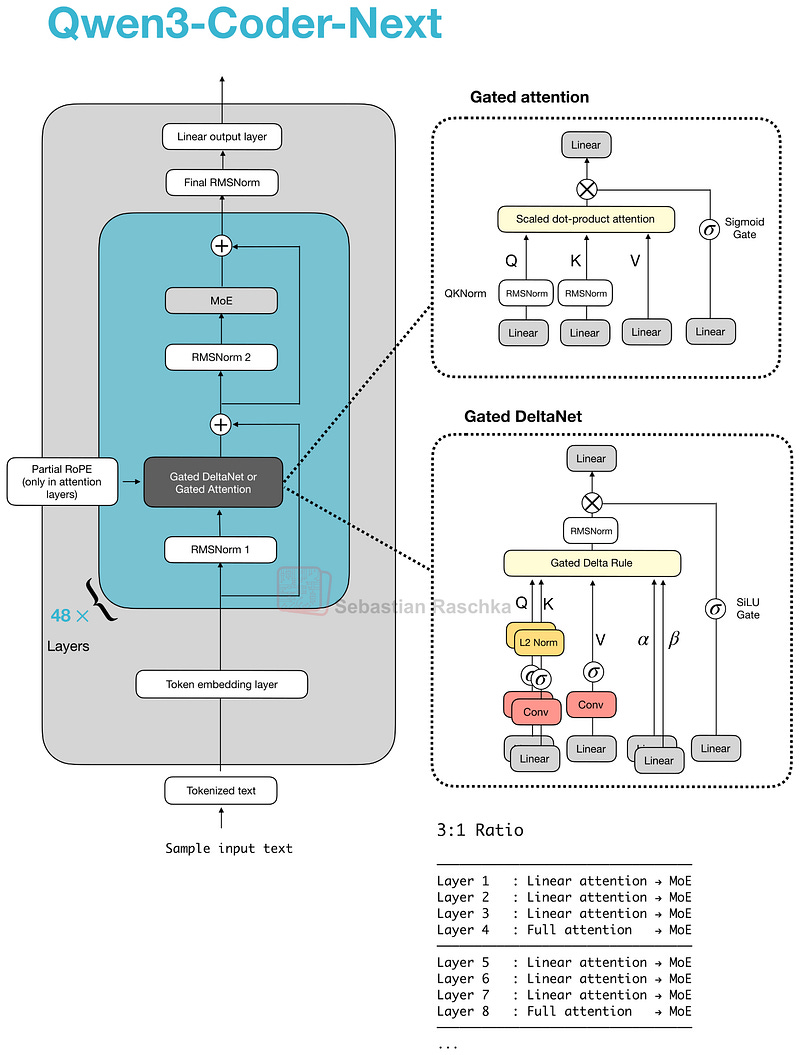
4. Qwen3-Coder-Next
발표일: 2026년 2월 3일
Qwen3-Coder-Next는 80B 파라미터(토큰당 3B 활성)의 코딩 특화 모델입니다.
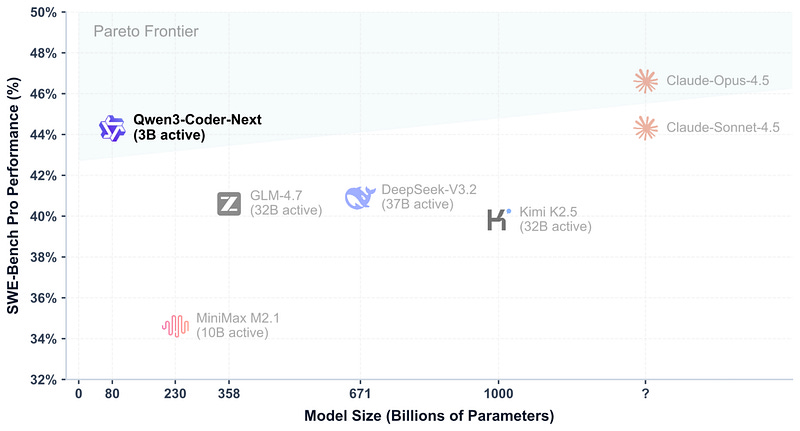
주요 특징
- Gated DeltaNet + Gated Attention 하이브리드: 3:1 비율로 혼합 사용
- 네이티브 262k 토큰 컨텍스트: 메모리 효율성 개선
- SWE-Bench Pro에서 Claude Sonnet 4.5와 동등한 성능
5. z.AI의 GLM-5
발표일: 2026년 2월 12일
GLM-5는 744B 파라미터(토큰당 40B 활성)의 플래그십 모델로, GPT-5.2 extra-high와 동등한 성능을 보입니다.
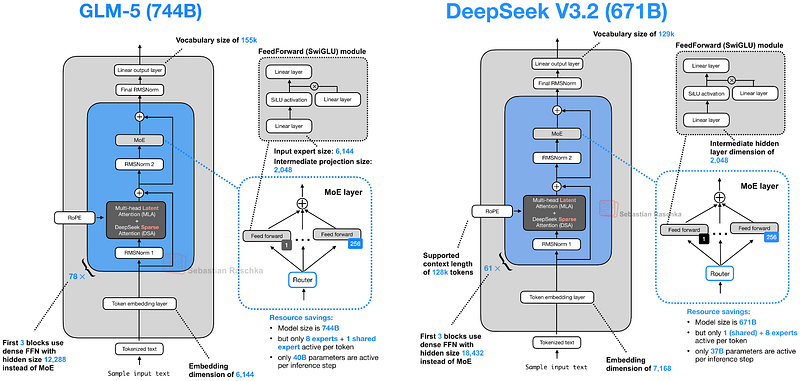
주요 특징
- Multi-Head Latent Attention (MLA): DeepSeek의 MLA 채택
- DeepSeek Sparse Attention: 긴 컨텍스트에서 추론 비용 감소
- 확장된 전문가 수: GLM-4.7의 160개에서 256개로 증가
6. MiniMax M2.5
발표일: 2026년 2월 12일
MiniMax M2.5는 230B 파라미터의 고효율 모델로, 오픈 라우터에서 가장 인기 있는 오픈 가중 모델 중 하나입니다.
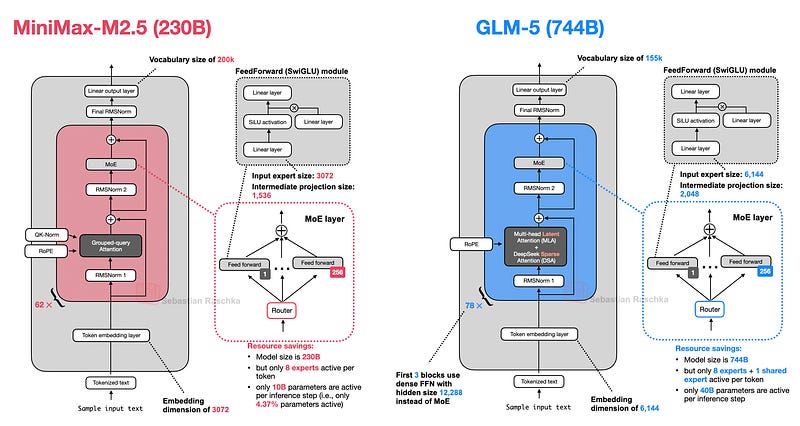
주요 특징
- 클래식 Grouped Query Attention: 추가 효율성 트윌크 없음
- 좋은 가성비: 더 작은 사이즈로 비슷한 성능 제공
- 코딩 성능: SWE-Bench Verified에서 GLM-5보다 약간 더 좋은 성능
7. Nanbeige 4.1 3B
발표일: 2026년 2월 13일
Nanbeige 4.1 3B는 로컬에서 실행 가능한 작은 모델로, Qwen3보다 훨씬 뛰어난 성능을 보입니다.
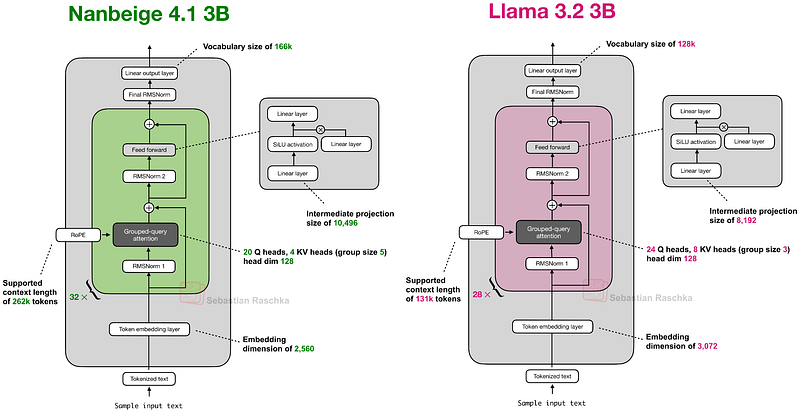
주요 특징
- Llama 3.2 3B와 유사한 아키텍처: SwiGLU, GQA 등
- Weight Tying 없음: Qwen3와 달리 입력 임베딩과 출력 레이어 가중치 미연결
- 온디바이스 사용 최적화: 로컬 실행을 위한 작은 사이즈
8. Qwen3.5
발표일: 2026년 2월 15일
Qwen3.5는 397B 파라미터(토큰당 17B 활성)의 MoE 모델로, Qwen3-Max보다 모든 벤치마크에서 우수한 성능을 보입니다.
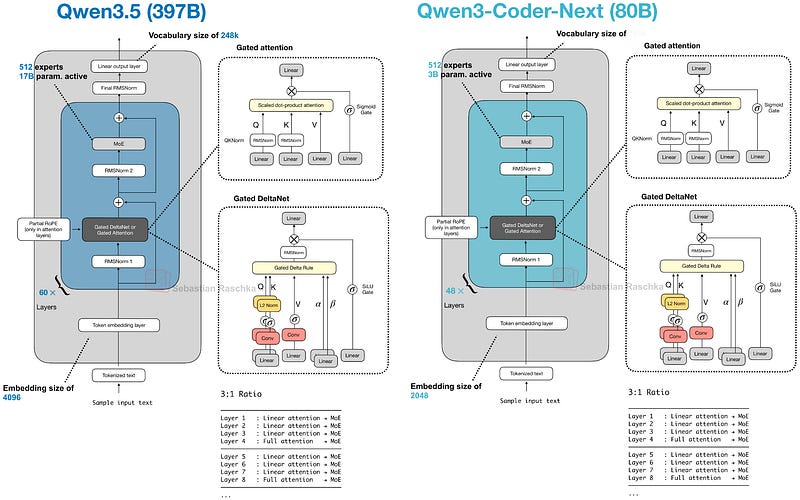
주요 특징
- 하이브리드 어텐션 채택: Qwen3-Next의 Gated DeltaNet 사용
- 멀티모달 지원: 기본 모델에서 네이티브 멀티모달 지원
- 에이전트 코딩 최적화: SWE-Bench Verified에서 GLM-5 및 MiniMax M2.5와 동등한 성능
9. Ant Group의 Ling 2.5 1T
발표일: 2026년 2월 16일
Ling 2.5는 1조 파라미터의 하이브리드 어텐션 모델로, Qwen3.5와 유사한 구조를 갖습니다.
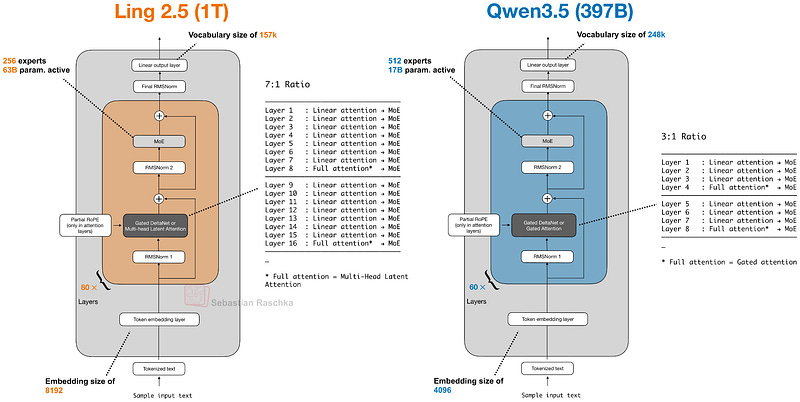
주요 특징
- Lightning Attention: Gated DeltaNet보다 간단한 순환 선형 어텐션
- Multi-Head Latent Attention: DeepSeek의 MLA 채택
- 높은 처리량: 32k 토큰 시퀀스에서 Kimi K2 대비 3.5배 높은 처리량
10. Cohere의 Tiny Aya
발표일: 2026년 2월 17일
Tiny Aya는 3.35B 파라미터의 다국어 지원 모델로, “가장 능력 있는 다국어 오픈 가중 모델”로 소개됩니다.
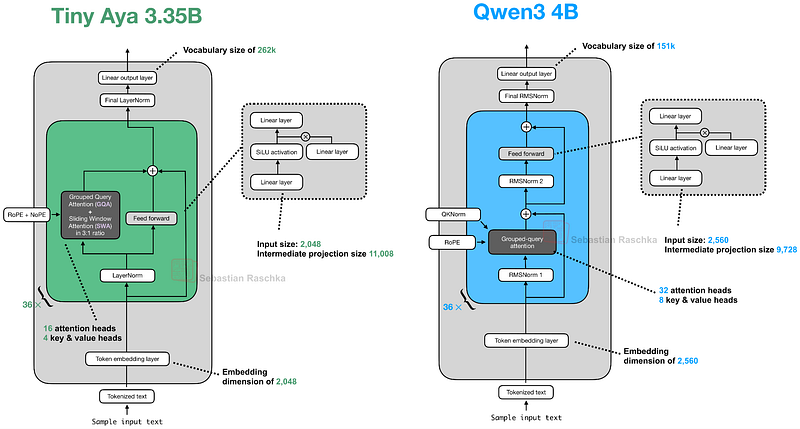
주요 특징
- Parallel Transformer Blocks: 어텐션과 MLP를 병렬로 계산
- 다양한 언어 최적화: global, fire, water, earth 버전으로 분류
- QK-Norm 제거: 긴 컨텍스트 성능 향상을 위해 QK-Norm 제거
결론
2026년 초 오픈 가중 LLM 릴리스의 주요 트렌드를 요약하면 다음과 같습니다:
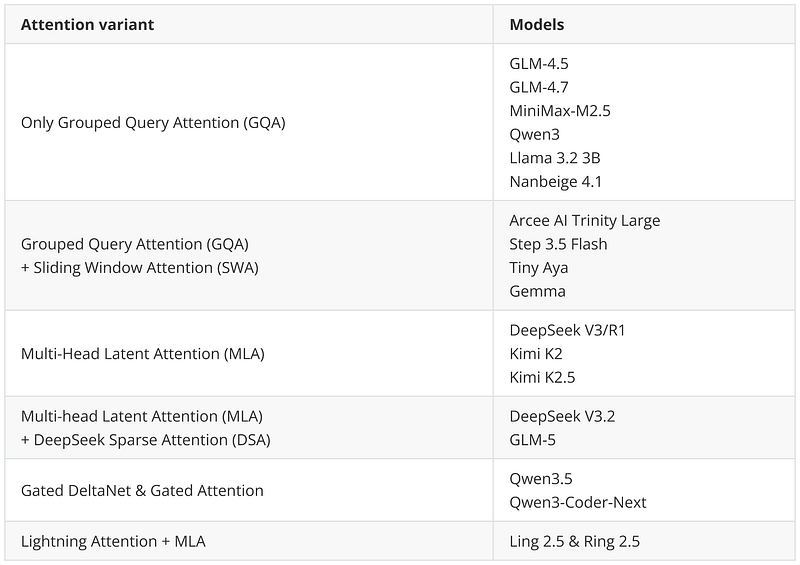
- 하이브리드 어텐션 채택: Qwen3.5, Ling 2.5 등이 DeltaNet, Lightning Attention 등 선형 어텐션을 기존 어텐션과 혼합
- MLA 및 Sparse Attention: Kimi K2.5, GLM-5, Ling 2.5가 DeepSeek의 효율성 기술 채택
- 클래식 트윌크도 여전히 유효: MiniMax M2.5, Nanbeige 4.1이 기본 GQA로도 우수한 성능 달성
참고
- 원본 글: Sebastian Raschka의 오픈 가중 LLM 아키텍처 10개
- 요약일: 2026-02-28
- 태그: LLM OpenWeight Architecture DeepSeek GLM Qwen