개요
Google Cloud AI Research, UIUC, MIT 공동 연구팀이 제안한 SkillOS는 LLM 에이전트가 스트리밍 태스크를 처리하면서 과거 경험으로부터 스킬을 축적·진화시키는 시스템이다. arXiv 2605.06614.
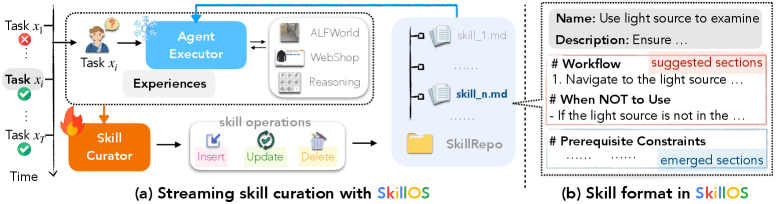 Figure 1: SkillOS 시스템 개요 — frozen executor와 trainable curator의 모듈러 구조
Figure 1: SkillOS 시스템 개요 — frozen executor와 trainable curator의 모듈러 구조
문제 정의
기존 LLM 에이전트는 태스크를 독립적으로(“one-off”) 처리한다. 즉, 이전 태스크에서 쌓은 경험이 다음 태스크에 전달되지 않는다.
이를 개선하려는 시도들의 한계:
- 수동 스킬 큐레이션 (Anthropic 등): 전문가가 직접 스킬을 작성해야 하므로 확장 불가
- 휴리스틱 기반 메모리 연산: 다운스트림 태스크 성능 피드백 없음
- 기존 RL 접근: 단기 스킬 적응에만 집중, 장기 스킬 저장소 진화 미지원
SkillOS 아키텍처
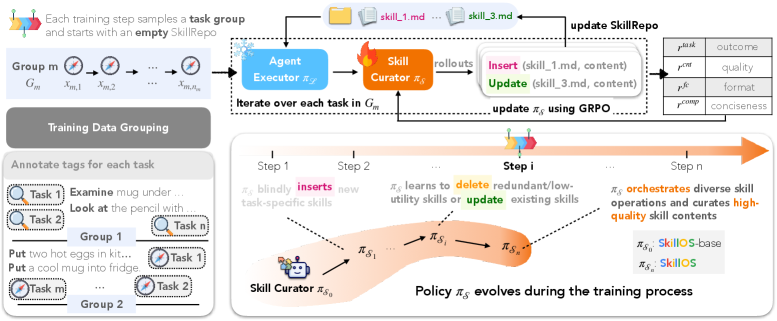 Figure 2: SkillOS 학습 파이프라인 — 그룹화된 태스크 스트림과 GRPO 최적화
Figure 2: SkillOS 학습 파이프라인 — 그룹화된 태스크 스트림과 GRPO 최적화
핵심 구성 요소
SkillRepo
- 외부 스킬 저장소
- 각 스킬은 Markdown 파일로 표현: YAML frontmatter + Markdown 형식의 instructions
- 파일 I/O 방식으로 관리
Agent Executor (frozen)
- BM25로 SkillRepo에서 관련 스킬 검색
- 검색된 스킬을 context에 포함하여 태스크 수행
- 훈련 중 파라미터 고정
Skill Curator (trainable)
- 태스크 trajectory와 정답 여부를 관찰
insert_skill,update_skill,delete_skill연산으로 SkillRepo 수정- RL로 훈련
스트리밍 스킬 큐레이션
태스크 시퀀스 D = {x₁, x₂, …, xT}에서:
- 앞선 태스크들의 trajectory를 관찰하여 SkillRepo 업데이트
- 뒤의 관련 태스크에서 변경된 SkillRepo의 효과를 평가
그룹화된 관련 태스크로 훈련 인스턴스를 구성하는 것이 핵심이다.
RL 훈련: GRPO + Composite Reward
GRPO (Group Relative Policy Optimization) 사용.
Composite Reward 4가지 구성요소:
- Task performance reward: 후속 태스크에서의 정답 여부
- Function call validity: insert/update/delete 연산의 유효성
- Skill content quality: 스킬 내용의 품질
- SkillRepo compactness: 저장소 크기 효율성
실험 결과
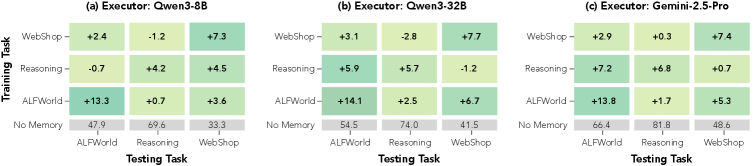 Figure 3: Cross-task 일반화 결과 — 3개 executor에서의 상대적 성능 향상
Figure 3: Cross-task 일반화 결과 — 3개 executor에서의 상대적 성능 향상
주요 벤치마크
| 벤치마크 | 유형 | 결과 |
|---|---|---|
| ALFWorld | multi-turn agentic | 3개 executor 모두에서 일관된 향상 |
| WebShop | multi-turn agentic | 평균 점수 및 성공률 향상 |
| GSM8K, MATH500, GPQA | 단일 턴 추론 | 정확도 향상 |
핵심 수치:
- 최대 +9.8% 성능 향상
- -6.0% interaction step 감소 (더 효율적인 태스크 수행)
- Agentic 태스크에서 단일 턴 추론보다 더 큰 향상 (절차적 지식이 더 재사용 가능)
일반화 능력
- 큐레이터를 Qwen3-8B, Qwen3-32B, Gemini-2.5-Pro에 적용 가능
- 추론 태스크에서 학습한 큐레이터가 agentic 태스크로 전이 성능 우수
- 8B 큐레이터가 Gemini-2.5-Pro를 직접 executor로 사용하는 것보다 우수
훈련 과정 분석
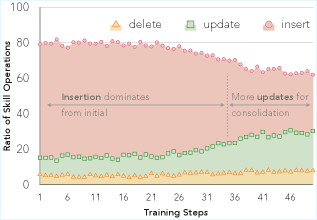 Figure 4: 큐레이터 연산 분포 변화 — insert/update/delete 비율의 훈련 과정 변화
Figure 4: 큐레이터 연산 분포 변화 — insert/update/delete 비율의 훈련 과정 변화
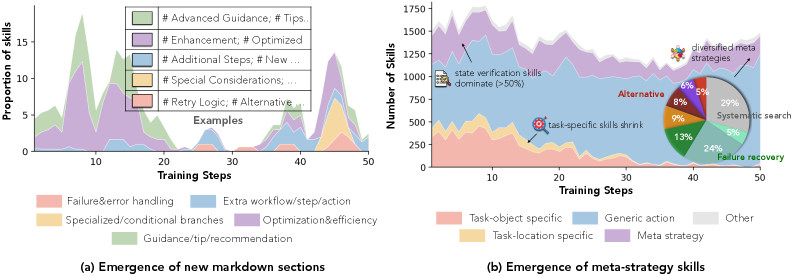 Figure 5: SkillRepo 진화 역학 — 스킬 내용과 저장소 구조의 변화
Figure 5: SkillRepo 진화 역학 — 스킬 내용과 저장소 구조의 변화
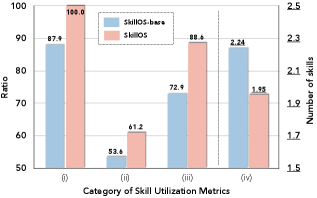 Figure 6: 스킬 활용 통계 비교
Figure 6: 스킬 활용 통계 비교
관찰된 패턴
- 훈련 초기:
insert_skill비율이 높음 → generic 섹션 추가 경향 - 훈련 후기:
update_skill,delete_skill비율 증가 → 더 타겟팅된 스킬 생성 - SkillRepo가 시간이 지남에 따라 더 풍부한 내부 구조와 higher-level meta-skills 발달
- 학습된 큐레이터는 더 적은 스킬로 더 타겟팅된 사용 패턴을 보임
이 논문이 말하고 싶은 것
LLM 에이전트가 frozen executor와 RL로 훈련된 trainable skill curator를 분리하면, 스트리밍 태스크 경험으로부터 재사용 가능한 스킬을 자동으로 축적·정제하여, 더 작은 모델이 더 큰 모델을 직접 사용하는 것보다 우수한 성능을 달성할 수 있다.