AI 에이전트에게 왜 “기억”이 필요한가
ChatGPT를 쓰다가 세션을 닫으면 모든 대화가 사라진다. 다음 세션에서 “아까 말한 그거”라고 해봤자 AI는 모른다. 이건 단순한 불편함이 아니라, AI 에이전트가 “진짜” 비서나 동료가 되기 위한 근본적인 장벽이다.
실제 배포 환경에서 AI 에이전트는 사용자의 취향, 과거 결정, 변경된 세계 상태를 며칠, 몇 주, 심지어 몇 달에 걸쳐 기억해야 한다. 인지과학은 인간의 기억을 작업 기억, 에피소드 기억, 의미 기억, 절차 기억으로 분류한다. 이 구분이 이제 LLM 에이전트 아키텍처에도 반영되고 있다.
이 포스트는 “Agent Memory Systems for Large Language Models: A Survey of Benchmarks, Architectures, and Performance” 논문을 기반으로, 에이전트 메모리 시스템의 전체 생태계를 정리한다.
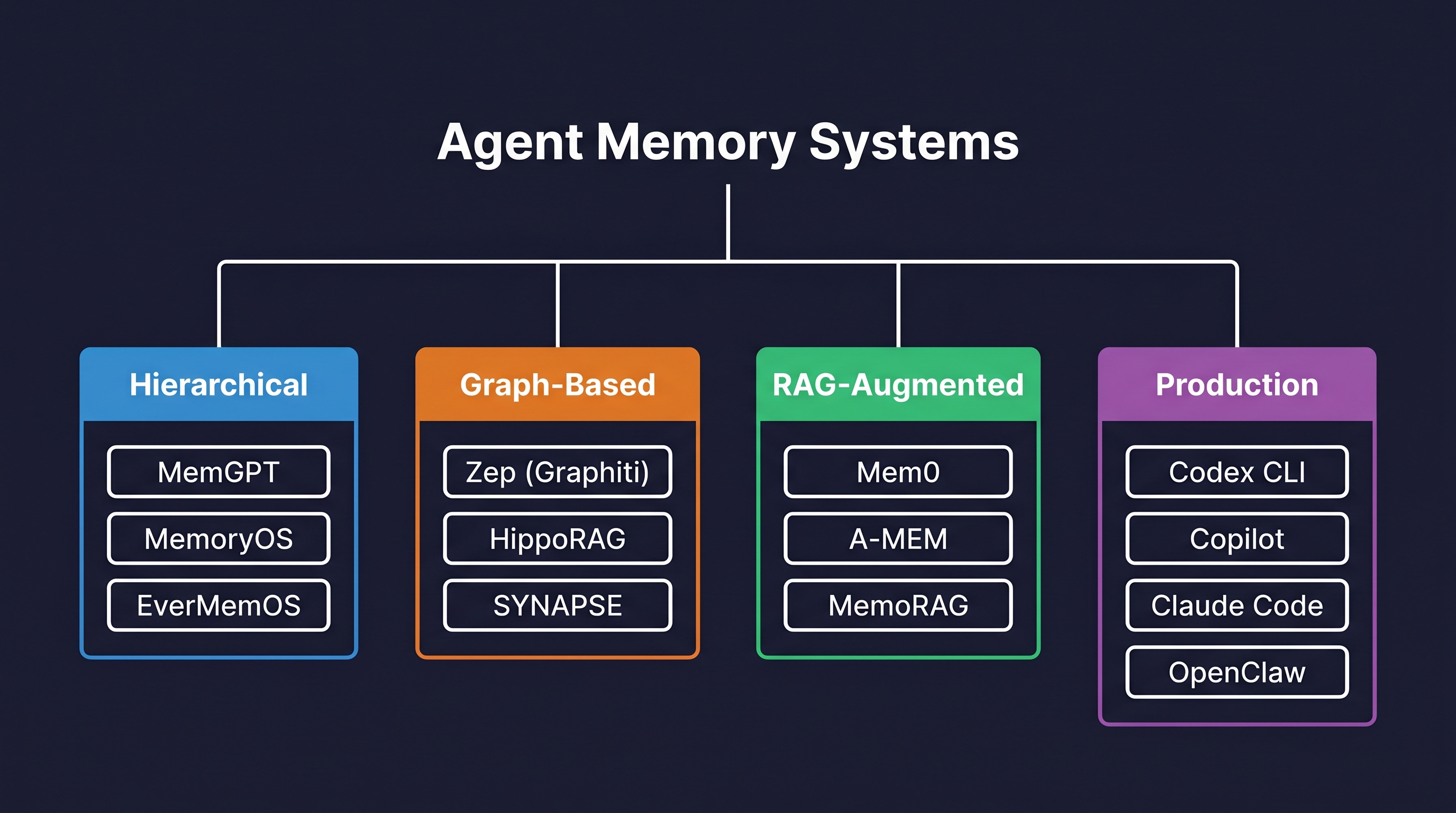
메모리 시스템 분류: 5가지 접근법
에이전트 메모리 구현은 크게 다섯 가지로 나뉜다.
1) 검색 기반 (Retrieval-Based) 어휘 검색(BM25/Grep), 밀도 벡터 검색(RAG), 그리고 이 둘을 결합한 하이브리드 방식. 대부분의 프로덕션 시스템이 이 방식을 기반으로 한다.
2) 그래프 기반 (Graph-Based) 지식 그래프를 활용해 엔티티 간 관계를 저장하고 시간적 유효성을 추적한다. Zep의 Graphiti, HippoRAG가 대표적.
3) LLM 매개 방식 (LLM-Mediated) LLM이 직접 무엇을 기억할지 판단한다. Mem0은 “선택적 쓰기” 방식으로 핵심 사실만 추출하고, Honcho는 “턴 캡처” 방식으로 대화를 기록한다.
4) 구조적/아키텍처 방식 (Structural) 컨텍스트 윈도우 관리, 계층형 페이징(MemGPT), 압축/요약 등. 하드웨어적 제약 안에서 기억을 관리하는 접근.
5) 파라메트릭 (Parametric) 모델 가중치에 직접 정보를 새겨넣는 방식. 파인튜닝/LoRA, KV 캐시 재사용 등. 가장 영구적이지만 수정이 가장 어렵다.
대부분의 실제 시스템은 두 가지 이상의 방식을 조합한다.
벤치마크: 얼마나 잘 기억하는가
LoCoMo
50개의 초장기 대화(평균 300턴, 9K 토큰, 최대 35세션)로 구성. 단일 홉 QA, 다중 홉 추론, 이벤트 요약, 멀티모달 대화 생성을 테스트한다. 인간 성능이 LLM을 ~36% 상회한다.
LongMemEval
6개 카테고리에 걸쳐 500개 질문. 대화당 평균 115K 토큰. 단일 세션, 지식 업데이트, 시간 추론, 다중 세션 회상을 테스트한다. 시간 추론이 모든 시스템에서 가장 어려운 카테고리다.
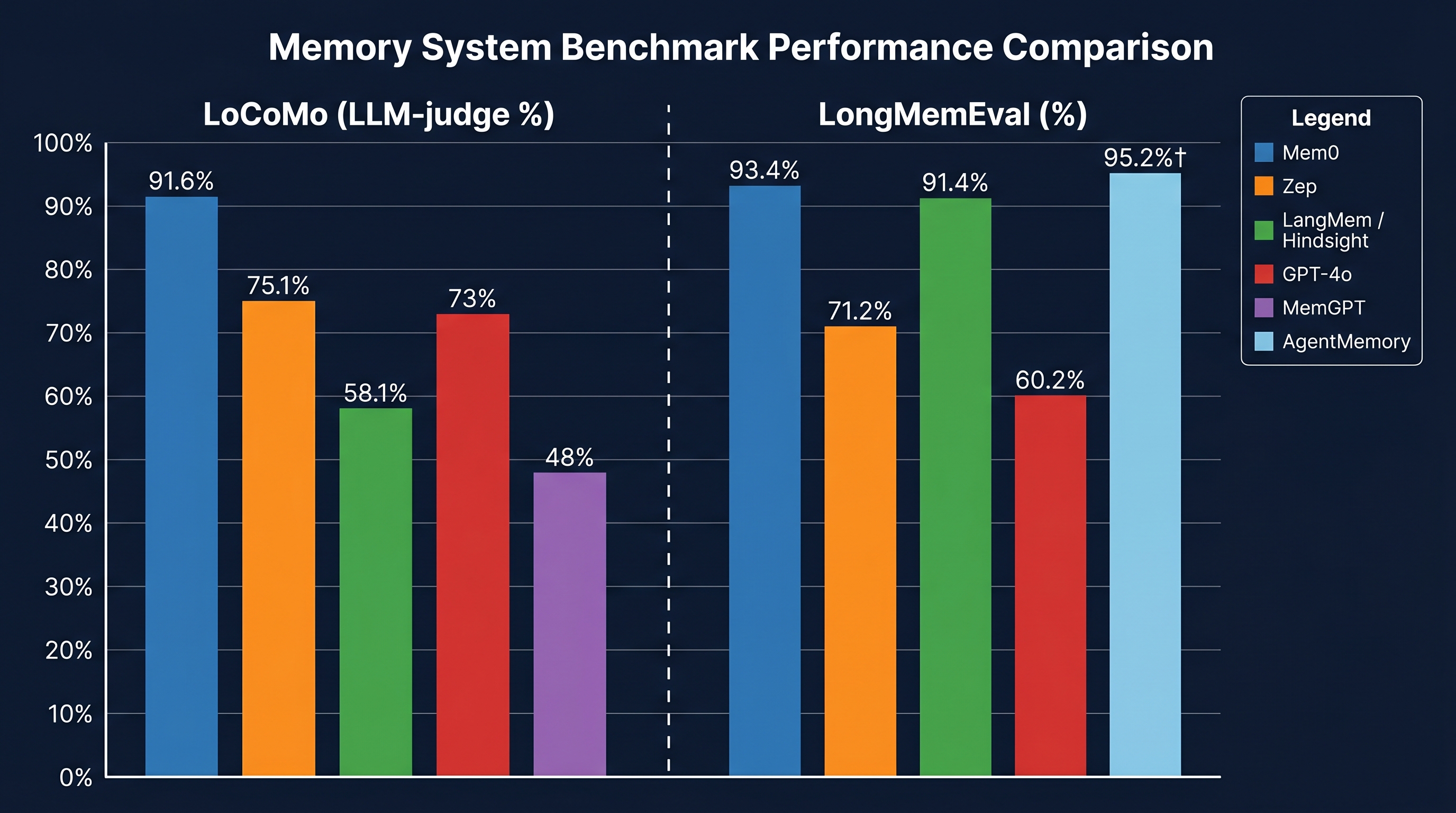
핵심 수치
| 시스템 | LoCoMo (LLM-judge) | LongMemEval |
|---|---|---|
| Mem0 (2026) | 91.6% | 93.4% |
| Hindsight | — | 91.4% |
| Mem0 (2025) | 67.1% | — |
| Zep | 75.1%* | 71.2% |
| LangMem | 58.1% | — |
| Full-context GPT-4o | ~73% | 60.2% |
| MemGPT | ~48% | — |
| AgentMemory | — | 95.2%† |
*Zep 자체 보고; Mem0 논문에서는 Zep을 66.0%로 측정 †AgentMemory는 Recall@5 기준으로 LLM-judge 점수와 직접 비교 불가
핵심 발견: 단일 승자는 없다. 시간 추론은 모든 시스템의 치명적 병목이다. Mem0이 LoCoMo에서 압도적이지만, LongMemEval에서는 Hindsight와 AgentMemory가 경쟁력 있다.
주요 아키텍처 심층 분석
Mem0: 동적 사실 추출
Mem0은 대화에서 핵심 사실을 동적으로 추출하고 세션 간에 통합한다. LoCoMo에서 91.6% LLM-judge 점수를 달성하면서도, 전체 컨텍스트 대비 91% 레이턴시 감소를 기록했다. “무엇을 기억할지”를 LLM이 판단하는 선택적 쓰기 방식이 핵심.
Zep: 시간 인식 그래프
Zep은 Graphiti라는 시간 인식 지식 그래프를 사용한다. 바이템포럴(bi-temporal) 유효성 윈도우로 “언제부터 언제까지 이 사실이 참이었는지”를 추적한다. LongMemEval에서 18.5% 정확도 개선. 하지만 시간 추론 카테고리에서는 여전히 어려움을 겪는다.
MemGPT: OS 영감 계층형 페이징
운영체제의 메모리 관리에서 영감을 받았다. 메인 컨텍스트, 리콜 데이터베이스, 아카이벌 벡터 스토어의 3계층 구조로 사실상 무제한 컨텍스트를 가능하게 한다. 하지만 LoCoMo에서 ~48%로 성능이 낮은 편.
Hindsight: 강화학습 기반 기억
오픈소스 20B 모델로 LongMemEval 91.4%를 달성. 4개의 논리적 메모리 네트워크와 반성(reflection) 레이어를 통해 풀 컨텍스트 GPT-4o를 능가한다.
프로덕션 코딩 도구는 어떻게 기억하는가
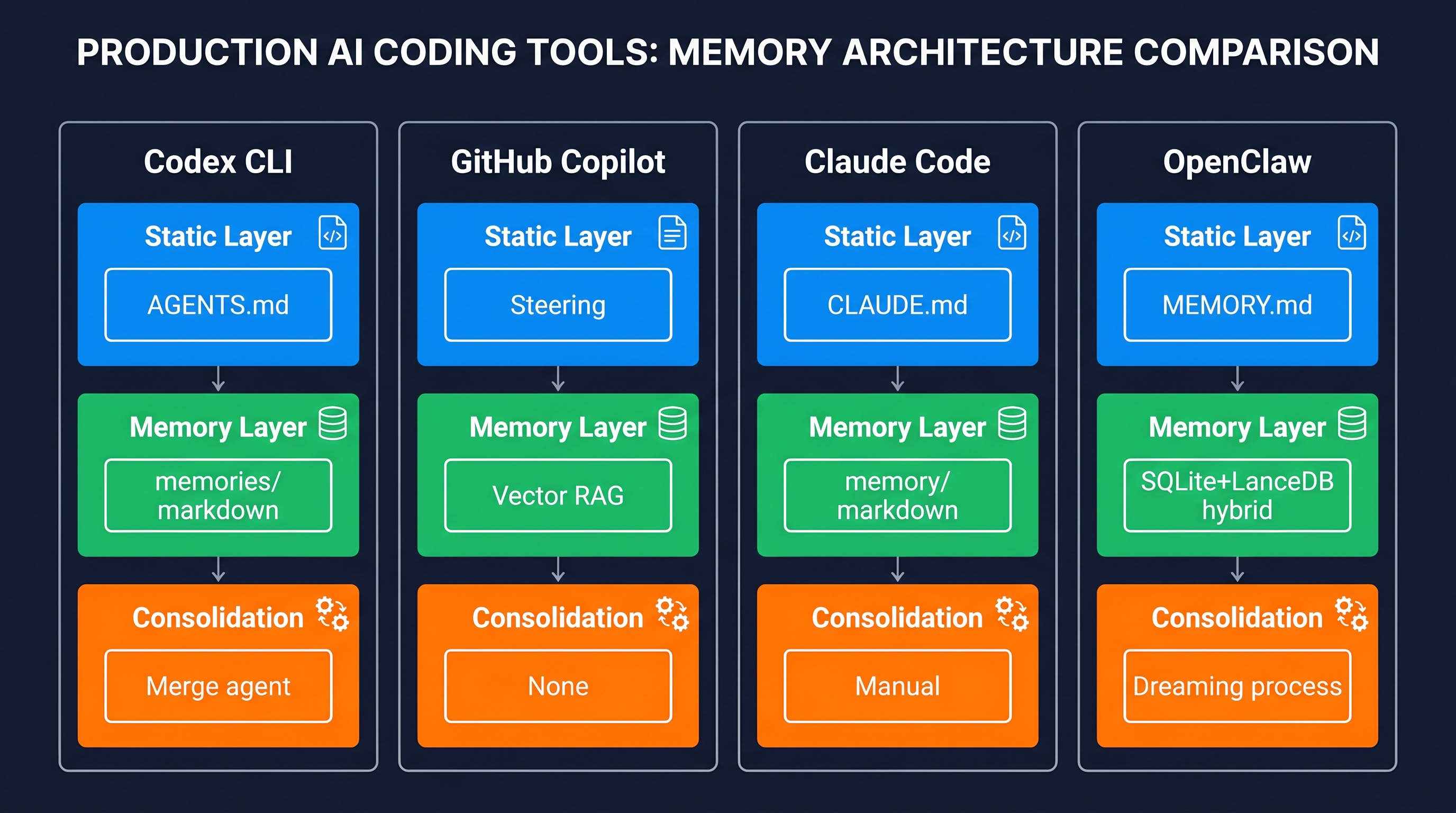
가장 흥미로운 발견은 4개의 주요 코딩 도구가 독립적으로 동일한 2계층 설계로 수렴했다는 점이다. 정적 명령 계층 + 생성 메모리 계층.
| Codex CLI | GitHub Copilot | Claude Code | OpenClaw | |
|---|---|---|---|---|
| 정적 계층 | AGENTS.md | Steering files | CLAUDE.md | MEMORY.md |
| 메모리 저장 | ~/.codex/memories/ | 독점 벡터 인덱스 | ~/.claude/projects/…/memory/ | SQLite / LanceDB |
| 벡터/RAG | 없음 | 있음 (MRL 임베딩) | 없음 | 선택 (하이브리드 70/30) |
| 세션 간 통합 | Lock-gated merge | 없음 | 수동 (에이전트 판단) | Dreaming 프로세스 |
| 오픈소스 | 예 | 아니오 | 예 (MIT) | 예 |
| 핵심 한계 | 옵트인; 지역 제한 | 요약 없음 | 벡터 검색 없음 | 플러그인 설정 필요 |
Codex CLI (OpenAI)
AGENTS.md를 세션 시작 시 주입하고, 스레드별 메모리를 ~/.codex/memories/에 마크다운으로 저장. memory_summary.md를 lock-gated merge agent가 통합. 하지만 옵트인이어야 하고, EEA/영국/스위스 지역 제한이 있다.
GitHub Copilot
Matryoshka Representation Learning(MRL)으로 훈련된 임베딩을 사용. 전 세대 대비 37.6% 검색 품질 개선, 8배 메모리 절약. 하지만 모델이 생성한 메모리 요약 기능이 없다. 사용자가 직접 steering files를 관리해야 한다.
Claude Code
CLAUDE.md를 디렉토리 순회로 자동 발견하여 시스템 프롬프트에 주입. 메모리는 마크다운 파일 + YAML 프론트매터. 텍스트 기반 검색만 제공하고 네이티브 벡터 임베딩은 없다. 감사 가능성과 인간 제어를 검색 정교함보다 우선시하는 설계.
OpenClaw
가장 다층적인 접근. MEMORY.md(장기), memory/YYYY-MM-DD.md(일일), DREAMS.md(통합 일기)의 파일 계층. 기본 SQLite 백엔드에서 BM25 키워드 검색 지원. 임베딩 제공자가 설정되면 **하이브리드 모드(70% 벡터 + 30% BM25)**로 전환. Dreaming 백그라운드 프로세스가 일일 노트의 신호를 점수화하여 MEMORY.md로 승격시키는 것이 특징—인간의 수면 기억 통합과 유사한 개념.
벡터 스토어 인프라 계층
메모리 시스템 아래에는 벡터 유사도 검색을 제공하는 인프라 계층이 있다.
| 스토어 | 백엔드 | 하이브리드 검색 | 로컬 모드 | p50 레이턴시 |
|---|---|---|---|---|
| LanceDB | Lance (Rust, 칼럼형) | BM25 + 벡터 | 서버리스 (파일) | 1-5ms |
| Qdrant | Rust, HNSW | Sparse + Dense | 임베디드/서버 | 2-8ms |
| Chroma | DuckDB / SQLite | 벡터 + 메타데이터 | 인프로세스 | 5-20ms |
| FAISS | C++ / BLAS | 벡터만 | 인프로세스 | <1ms |
FAISS가 가장 빠르지만 내장 영속성과 하이브리드 검색이 없다. LanceDB가 에이전트 메모리 워크로드에 가장 적합—제로 서버, 하이브리드 검색, 경쟁력 있는 레이턴시.
남은 과제: 8개의 열린 질문
1. 시간 추론. 모든 시스템이 시간 인덱스 쿼리에서 어려움을 겪는다. OpenAI Memory는 시간 관련 질문에서 21.7%만 정답. Zep의 바이템포럴 유효성 윈도우가 부분적 해결책.
2. 규모 저하. 1M 토큰 이상에서 성능이 급격히 저하. 계층형 에빅션 전략이 완화하지만 검색 레이턴시 페널티를 유발.
3. 벤치마크 커버리지. LoCoMo와 LongMemEval은 대화형 회상만 테스트. 에이전트 워크플로우 메모리는 평가되지 않는다. 코딩 에이전트 특화 벤치마크가 필요.
4. 인프라-시스템 공동 설계. 벡터 스토어 백엔드 선택이 레이턴시와 하이브리드 검색 능력에 큰 영향을 미치지만, 대부분의 논문이 블랙박스로 취급.
5. 통합 충실도. 자동 통합(OpenClaw Dreaming, Codex merge)은 완전성과 컨텍스트 예산의 균형을 맞춰야 한다. 검증 가능한 커버리지 보증이 없다.
6. 도구 경계 간 메모리. CLAUDE.md/AGENTS.md가 암묵적 크로스 툴 컨벤션이지만, 표준 메모리 핸드오프 프로토콜이 없다. MCP(Model Context Protocol)와 유사한 표준이 필요.
7. 프라이버시와 보안. 멀티유저 메모리 네이밍스페이스, 메모리 포이즈닝 공격에 대한 표준 방어가 부재.
8. 평가 표준화. 평가 LLM(gpt-4o-mini vs gpt-4.1-mini)이 다르면 점수를 직접 비교할 수 없다. 고정된 오픈웨이트 평가 모델 채택이 필요.
결론
에이전트 메모리 시스템은 단순한 RAG에서 정교한 계층형/그래프 아키텍처로 빠르게 성숙하고 있다. Mem0, Hindsight, Zep이 대화 벤치마크의 현재 SOTA를 차지하고 있다.
하지만 진짜 이야기는 프로덕션 코딩 도구에 있다. Codex CLI, Copilot, Claude Code, OpenClaw가 독립적으로 동일한 설계로 수렴했다는 사실은, 파일 기반 정적 계층 + 생성 메모리 계층이 현재 실무에서 검증된 패턴이라는 의미다.
다음 세대 에이전트 메모리의 핵심 과제는 시간 추론, 통합 충실도, 평가 표준화다. 그리고 무엇보다, 코딩 에이전트가 매일 필요로 하는 워크플로우 메모리를 평가할 수 있는 새로운 벤치마크가 시급하다.
참고
- 논문: “Agent Memory Systems for Large Language Models: A Survey of Benchmarks, Architectures, and Performance”
- Mem0 | Zep | MemGPT/Letta | AgentMemory
- OpenClaw | LanceDB