배포된 AI 에이전트에게 새로운 환경이 주어졌다고 칩시다. 정답도 없고, 가이드도 없고, 피드백도 없습니다. 오직 태스크 프롬프트 하나만 덩그러니 놓여 있죠.
이 상황에서 에이전트가 스스로 무엇을 배워야 할지 결정하고, 스스로 연습 문제를 만들어서, 스스로 실력을 키울 수 있을까요?
Lehigh University, Salesforce AI Research, Harvard Medical School 등의 연구진이 이 질문에 대한 답으로 OpenSkill을 제안했습니다. (논문 링크, 코드)
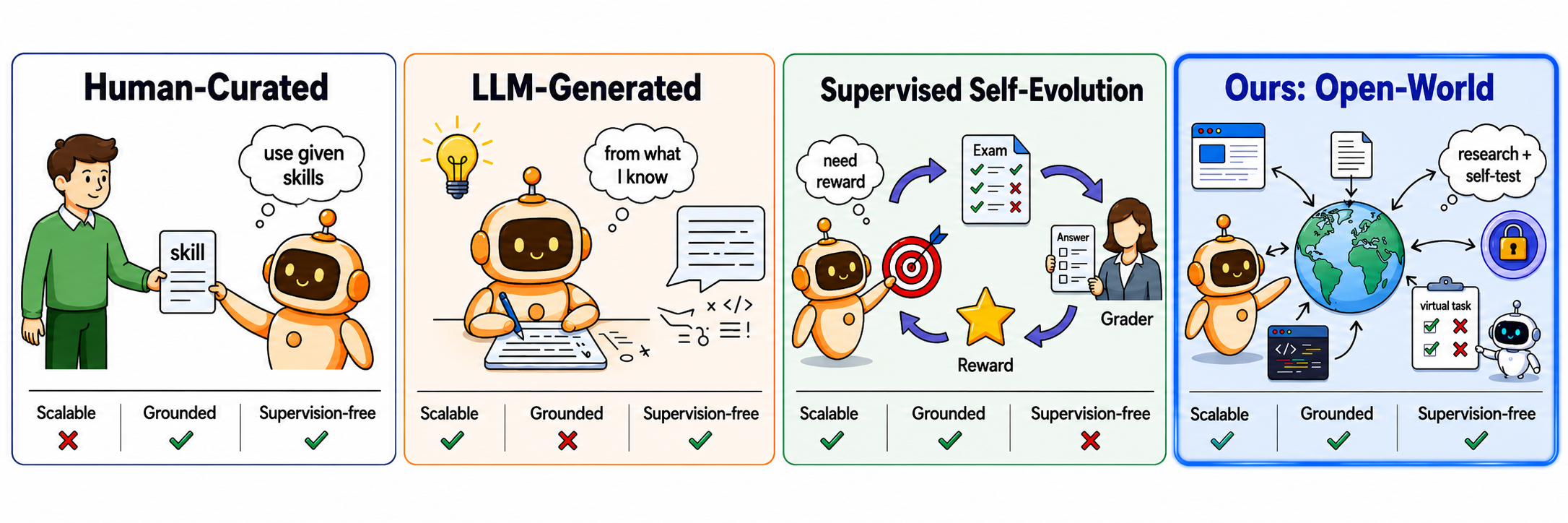
기존 자가진화 에이전트의 딜레마
에이전트가 배포 이후에도 계속 배우려면 두 가지가 필요합니다. 무엇을 배울지(스킬)와 잘 배웠는지 확인할 방법(검증).
문제는 기존 방법들이 이 둘 중 하나를 이미 가지고 있다고 가정한다는 겁니다.
- 인간이 미리 스킬을 작성해두면 비싸고 확장이 안 됩니다
- 모델이 아는 것만으로 스킬을 만들면 최신 정보나 도메인 지식이 부족합니다
- 성공한 실행 기록에서 스킬을 추출하려면, 일단 성공을 해야 합니다
- 정답이나 보상 신호로 피드백을 받으려면, 정답이 있어야 합니다
현실 세계에 배포된 에이전트는 이런 걸 하나도 못 갖춘 채 시작하는 경우가 대부분입니다.
열린 세상에서의 자가진화: 어떻게 돌아가나
OpenSkill의 핵심 아이디어는 단순합니다. 인터넷이라는 열린 세상이 이미 거대한 교과서이자 연습장이라는 거죠.
프레임워크는 세 단계로 구성됩니다:
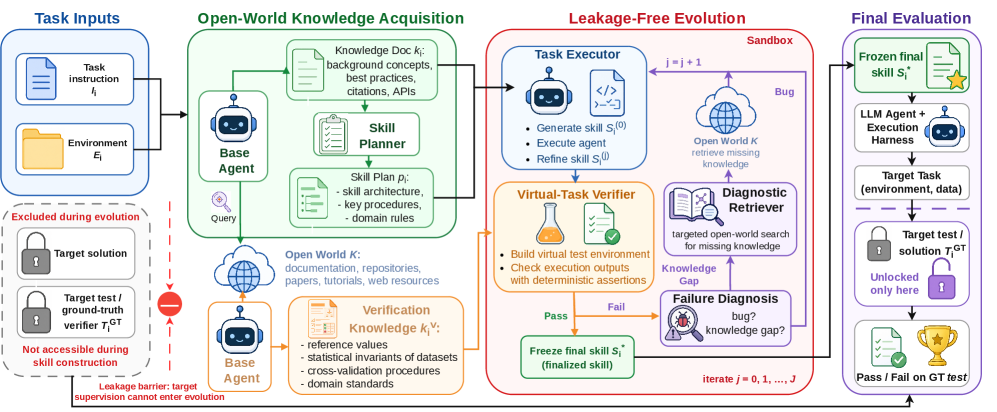
1단계: 열린 세상에서 지식 수집
태스크 프롬프트만 보고 에이전트가 할 일은 두 가지입니다.
첫째, 배울 지식을 찾습니다. 공식 문서, 깃허브 저장소, 튜토리얼, 논문 등에서 관련 배경지식, API 사용법, 베스트 프랙티스를 검색해서 가져옵니다. 이걸로 스킬 초안을 어떻게 구성할지 계획까지 세웁니다.
둘째, 검증 앵커를 찾습니다. 나중에 “내가 제대로 배웠나?” 확인할 수 있는 독립적인 사실들을 모읍니다. 공식 문서에 나오는 기댓값, 잘 알려진 데이터셋의 통계, 라이브러리 함수의 출력 형식 같은 거죠. 이건 정답이 아닙니다. 그냥 객관적으로 확인 가능한 사실들입니다.
중요한 건, 검색할 때 벤치마크 이름이나 정답 식별자를 전부 필터링해서 정답 유출(leakage)을 원천 차단한다는 겁니다.
2단계: 가상 테스트로 스킬 다듬기
에이전트가 1단계에서 얻은 지식으로 스킬 초안을 작성합니다. 그리고 1단계에서 모은 검증 앵커를 바탕으로 가상 테스트 스위트를 스스로 만듭니다.
예를 들어, 어떤 데이터 처리 태스크라면:
- “공개 데이터셋의 알려진 행 수와 일치하는가?”
- “표준 메트릭이 예상 범위 안에 있는가?”
- “문서화된 출력 형식을 따르는가?”
이런 식으로 정답을 모르면서도 객관적으로 검증 가능한 테스트를 만듭니다.
스킬을 실행하고 가상 테스트로 채점합니다. 통과하지 못하면, 실패 원인을 분석해서 스킬을 수정합니다. 지식 갭이면 다시 검색해서 메우고, 버그면 코드를 고치고. 최대 3라운드 반복합니다.
3단계: 제로샷 배포
다듬어진 스킬을 타겟 에이전트에 그대로 넘겨줍니다. 여기서야 비로소 숨겨둔 정답과 만납니다. 학습 과정 내내 정답은 한 번도 쓰인 적이 없습니다.
그리고 스킬은 모델 가중치가 아니라 텍스트 아티팩트이기 때문에, A모델에서 만든 스킬을 B모델에 그대로 쓸 수 있습니다.
결과: 감독 없이도 최고 성능
세 개 벤치마크(SkillsBench, SocialMaze, ScienceWorld), 두 개 타겟 에이전트(Claude Opus 4.6, GPT 5.2)에서 실험했습니다.
SkillsBench 11개 도메인 평균에서 OpenSkill은 모든 자동화 베이스라인을 상회했습니다. 가장 강력한 클로즈드 월드 베이스라인 대비 +8.9 / +8.8 포인트 차이.
특히 인상적인 건 두 가지입니다:
- 모델 간 전이: 한 모델로 만든 스킬을 다른 모델에 적용해도 성능이 유지됩니다. 모델별 재적응이 필요 없습니다.
- 자체 검증기 품질: 정답을 한 번도 안 보고 만든 가상 테스트가 실제 정답의 88.9% 의도를 커버합니다. 유령을 모르면서 유령이 있는지 확인하는 것 같은 건데, 실제로 잘 맞는 거죠.
왜 이게 중요한가
지금까지 에이전트 자가진화 연구는 대부분 “정답이 있는 환경”에서 이루어졌습니다. 벤치마크에서 통과하면 학습하고, 실패하면 수정하는 식이죠.
하지만 현실 세계엔 정답이 없습니다. 고객사에 배포된 에이전트가 “이 태스크의 정답”을 어디서 구하나요? 새로운 API가 나왔을 때, 누가 에이전트에게 사용법을 가르쳐주나요?
OpenSkill이 제시하는 방향은 이 문제에 대한 하나의 답입니다. 열린 세상 자체를 교과서이자 연습장으로 활용하라. 에이전트가 스스로 배울 것을 정하고, 스스로 연습 문제를 만들고, 스스로 채점하는 루프를 외부 감독 없이 부트스트래핑하는 방법.
물론 한계도 있습니다. 검증 앵커를 찾을 수 없는 도메인에서는 가상 테스트 품질이 떨어질 수 있고, 지식 수집 품질이 검색에 크게 의존합니다. 하지만 “정답 없이 시작하는 에이전트 자가진화”라는 문제 설정 자체가 현실 배포 시나리오에 훨씬 가깝다는 점에서, 앞으로의 연구 방향을 가리키는 의미 있는 작업입니다.
참고: Dingjie Song et al., “OpenSkill: Open-World Self-Evolution for LLM Agents”, arXiv:2606.06741, 2026. 논문 | 코드