DeepSeek-V4-Pro / Flash 공개 정리: 100만 토큰 컨텍스트와 벤치마크 결과
DeepSeek가 V4 시리즈 프리뷰를 올렸음. 핵심은 명확함. 100만 토큰 컨텍스트를 지원하는 대형 MoE 모델 2종을 동시에 공개했다는 점임.
- DeepSeek-V4-Pro: 1.6T 파라미터, 49B 활성화
- DeepSeek-V4-Flash: 284B 파라미터, 13B 활성화
- 둘 다 1M context 지원
한마디로, “길게 보고 끝까지 가는 모델” 쪽으로 크게 밀어붙였음.
먼저 스펙부터
| 모델 | 총 파라미터 | 활성 파라미터 | 컨텍스트 | 정밀도 |
|---|---|---|---|---|
| DeepSeek-V4-Flash-Base | 284B | 13B | 1M | FP8 Mixed |
| DeepSeek-V4-Flash | 284B | 13B | 1M | FP4 + FP8 Mixed |
| DeepSeek-V4-Pro-Base | 1.6T | 49B | 1M | FP8 Mixed |
| DeepSeek-V4-Pro | 1.6T | 49B | 1M | FP4 + FP8 Mixed |
뭐가 바뀌었나
1) 하이브리드 어텐션
CSA(Compressed Sparse Attention)와 HCA(Heavily Compressed Attention)를 섞은 구조임. 1M 토큰 설정에서 DeepSeek-V4-Pro는 DeepSeek-V3.2 대비 단일 토큰 추론 FLOPs 27%, **KV cache 10%**만 쓴다고 밝힘.
즉, 긴 컨텍스트를 그냥 “넣을 수 있다” 수준이 아니라 돌릴 수 있게 만든 쪽임.
2) mHC와 Muon
- mHC(Manifold-Constrained Hyper-Connections): 잔차 연결을 강화해서 깊은 층에서도 신호가 더 안정적으로 흐르도록 설계
- Muon optimizer: 더 빠른 수렴과 학습 안정성을 노림
3) 32T 토큰 프리트레이닝
두 모델 모두 32T+ 토큰으로 사전학습했고, 그 뒤에 두 단계 포스트트레이닝을 붙였음.
- SFT + RL(GRPO)로 도메인별 전문가를 키움
- 이후 on-policy distillation로 통합
결국 한 모델 안에 여러 전문성을 묶어 넣는 방식임.
reasoning mode도 나뉘어 있음
DeepSeek-V4-Pro / Flash는 세 가지 모드를 지원함.
| 모드 | 특징 | 용도 |
|---|---|---|
| Non-think | 빠르고 직관적 | 일상 업무, 낮은 리스크 |
| Think High | 느리지만 더 정확 | 복잡한 문제 해결, 계획 |
| Think Max | reasoning 최대화 | 모델 성능의 경계 탐색 |
이건 단순 챗봇보다 작업 난이도에 맞춰 생각량을 조절하는 구조에 가까움.
벤치마크 핵심만 뽑으면
Base 모델
| 벤치마크 | V4-Flash-Base | V4-Pro-Base |
|---|---|---|
| AGIEval | 82.6 | 83.1 |
| MMLU | 88.7 | 90.1 |
| MMLU-Pro | 68.3 | 73.5 |
| MultiLoKo | 42.2 | 51.1 |
| Simple-QA verified | 30.1 | 55.2 |
| SuperGPQA | 46.5 | 53.9 |
| FACTS Parametric | 33.9 | 62.6 |
| LongBench-V2 | 44.7 | 51.5 |
눈에 띄는 건 Simple-QA verified, FACTS Parametric, LongBench-V2임. 긴 문맥과 사실성, 지식 활용에서 Pro가 확실히 앞섰음.
Pro Max vs frontier 모델
DeepSeek는 Pro Max를 여러 상위 모델과 직접 비교했음. 여기서도 눈에 띄는 수치가 꽤 많음.
- MMLU-Pro: 87.5
- SimpleQA-Verified: 57.9
- GPQA Diamond: 90.1
- LiveCodeBench: 93.5
- Codeforces: 3206
- HMMT 2026 Feb: 95.2
- IMOAnswerBench: 89.8
- Terminal Bench 2.0: 67.9
- SWE Pro: 55.4
- BrowseComp: 83.4
- GDPval-AA: 1554
- Toolathlon: 51.8
정리하면 이쪽도 코딩, 수학, 장문맥, 에이전트형 작업을 전부 같이 밀고 있음.
모드별 비교도 의미 있음
DeepSeek는 Flash / Pro 각각에 대해 Non-think, High, Max 모드를 같이 제시했음. 숫자 변화가 꽤 분명함.
| 항목 | Flash Non-think | Flash High | Flash Max | Pro Non-think | Pro High | Pro Max |
|---|---|---|---|---|---|---|
| MMLU-Pro | 83.0 | 86.4 | 86.2 | 82.9 | 87.1 | 87.5 |
| SimpleQA-Verified | 23.1 | 28.9 | 34.1 | 45.0 | 46.2 | 57.9 |
| GPQA Diamond | 71.2 | 87.4 | 88.1 | 72.9 | 89.1 | 90.1 |
| Terminal Bench 2.0 | 49.1 | 56.6 | 56.9 | 59.1 | 63.3 | 67.9 |
| BrowseComp | - | 53.5 | 73.2 | - | 80.4 | 83.4 |
| HLE w/ tools | - | 40.3 | 45.1 | - | 44.7 | 48.2 |
이 표만 봐도 “생각을 더 시키면 결과가 더 좋아진다”는 구조가 꽤 잘 보임.
공식 벤치마크 이미지
공식 벤치마크 이미지는 Pro 페이지와 Flash 페이지에 같은 파일로 들어가 있었음. 그래서 아래 두 이미지는 각 페이지에 실린 벤치마크 결과를 그대로 담은 것임.
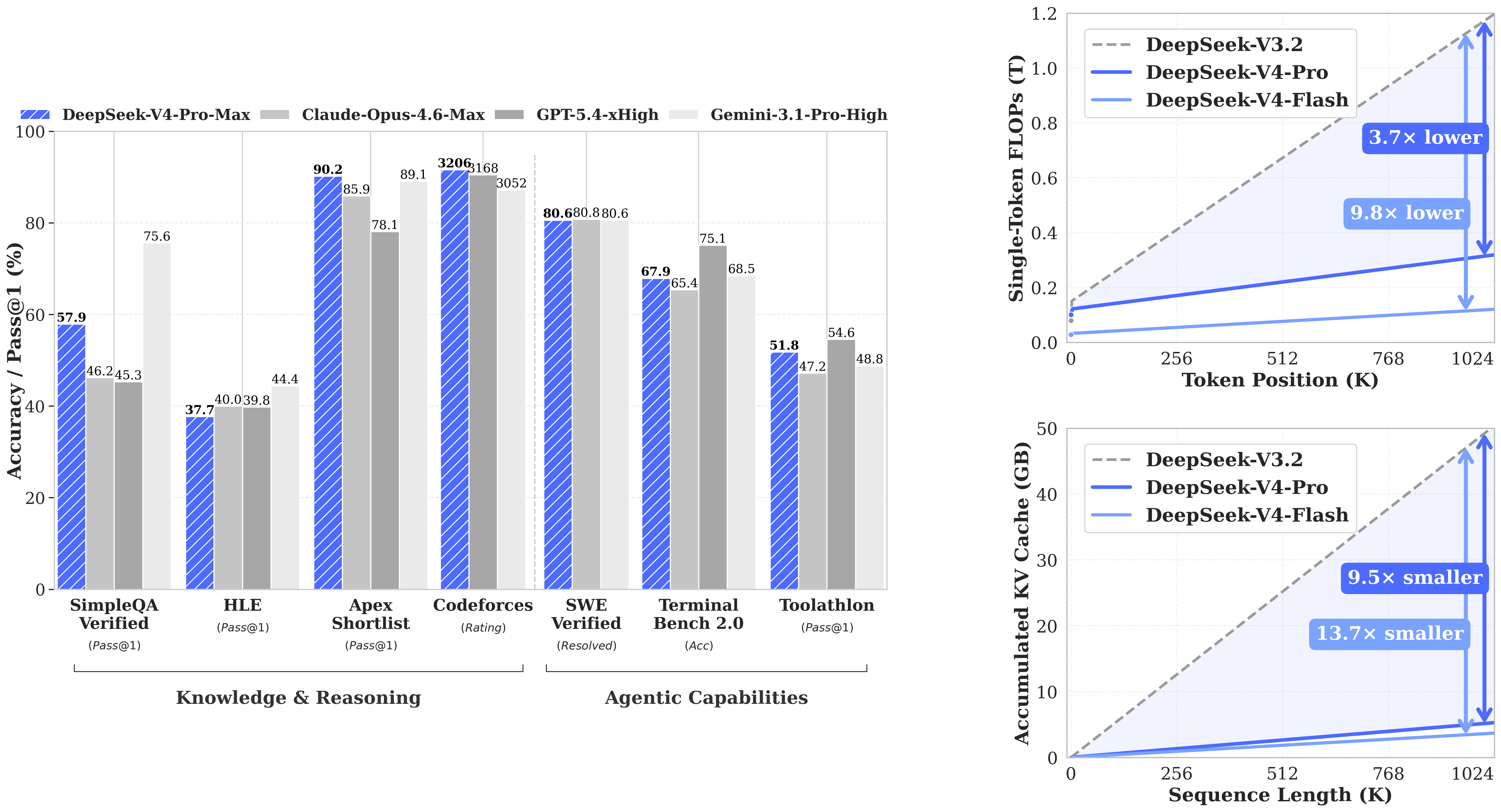
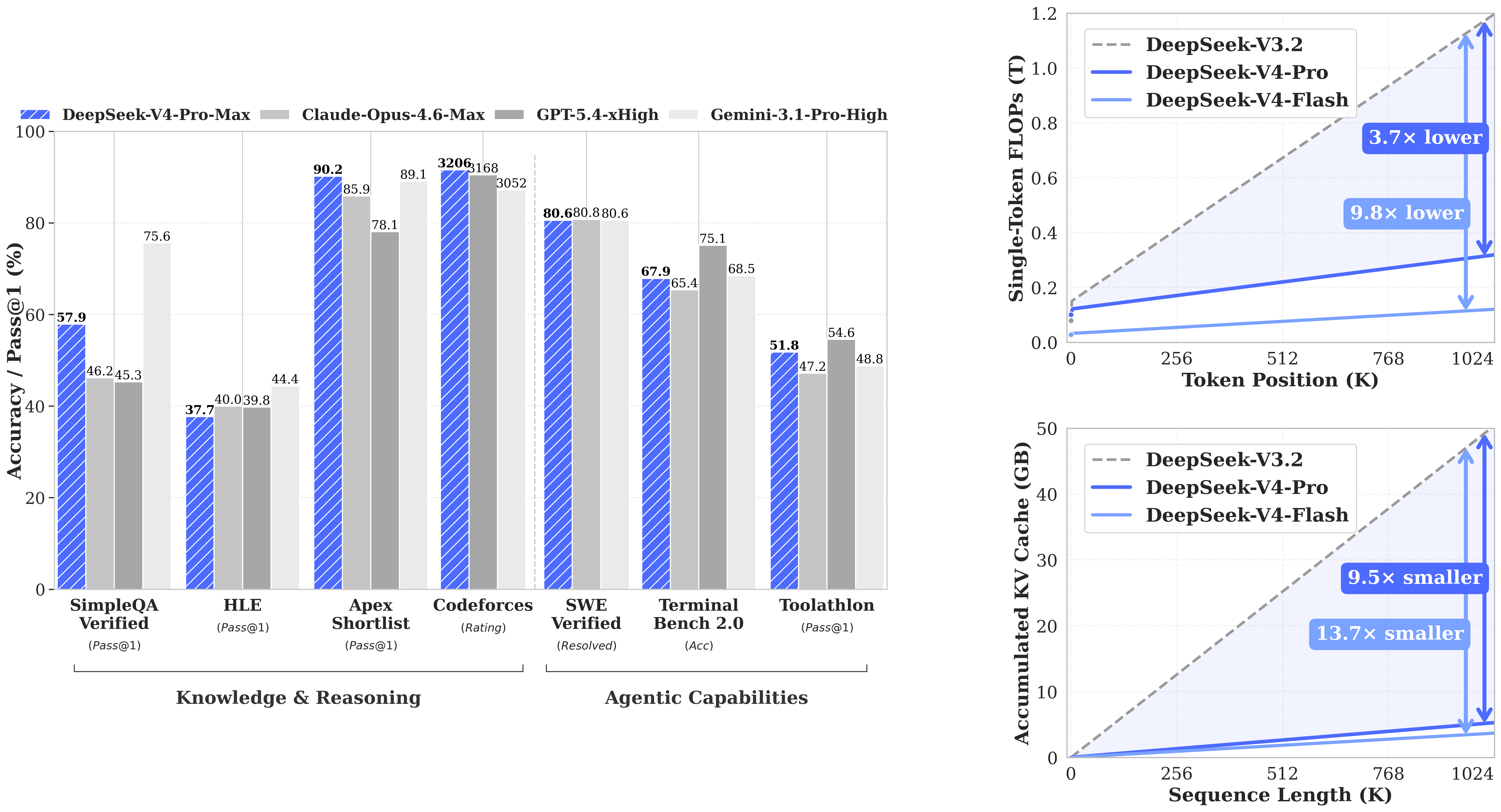
두 장이 같은 파일처럼 보이는 건, Hugging Face가 두 모델 페이지에 동일한 성능 차트를 넣었기 때문임.
이 소식의 포인트
DeepSeek-V4는 그냥 “큰 모델 하나 더 나왔다”가 아님.
- 100만 토큰 컨텍스트
- MoE 효율
- 하이브리드 어텐션
- reasoning mode 분리
- 긴 문맥과 에이전트 작업 강화
이 조합이 핵심임. 다시 말해, 길게 읽고, 오래 생각하고, 실전 작업까지 버티는 모델로 가고 있음.
누가 보면 좋은가
- 긴 문서 / 논문 / 로그를 다루는 사람
- 코딩 에이전트를 붙이는 사람
- 사실성, 장문맥, 도구 사용이 중요한 사람
- 오픈소스 최상위권 모델 흐름을 보는 사람
참고 링크
- Pro: https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro
- Flash: https://huggingface.co/deepseek-ai/DeepSeek-V4-Flash
- Technical Report PDF: https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/resolve/main/DeepSeek_V4.pdf
- 같이 보면 좋은 글: GPT-5.5 공개 정리