Claude Code에 흥미로운 변화가 들어왔다. 이제 Claude가 작업마다 자기만의 하네스, 그러니까 여러 하위 에이전트를 어떻게 부르고, 어떤 순서로 검증하고, 어디서 멈출지를 정하는 실행 구조를 즉석에서 만들 수 있다.
이 기능의 이름은 동적 워크플로우(dynamic workflows)다. 멋진 이름이지만 핵심은 단순하다. 긴 작업을 한 모델의 기억력과 성실함에 맡기지 않고, 작업 구조 자체가 모델을 견제하게 만드는 것.
왜 그냥 Claude Code에게 맡기면 부족할까
평범한 코딩 작업이라면 기존 Claude Code만으로도 충분하다. 파일 읽고, 수정하고, 테스트하고, 다시 고치면 된다. 문제는 작업이 길어질 때다. 예를 들어 50개 보안 항목을 모두 점검해야 하거나, 1,000개 지원 티켓을 분류해야 하거나, 보고서의 모든 사실 주장에 출처를 붙여야 하는 경우다.
이런 작업에서 한 컨텍스트 안의 에이전트는 세 가지 약점을 보인다. 중간까지만 하고 끝났다고 말하는 게으름. 자기가 낸 답을 스스로 후하게 보는 자기편향. 그리고 긴 대화와 압축을 거치며 처음 목표가 흐려지는 목표 이탈.
동적 워크플로우는 이 약점을 “더 똑똑한 프롬프트”로만 해결하려 하지 않는다. 아예 역할을 나눈다. 찾는 에이전트, 반박하는 에이전트, 합치는 에이전트, 멈춰도 되는지 판단하는 에이전트를 따로 둔다.
정적 워크플로우보다 중요한 건 맞춤성이다
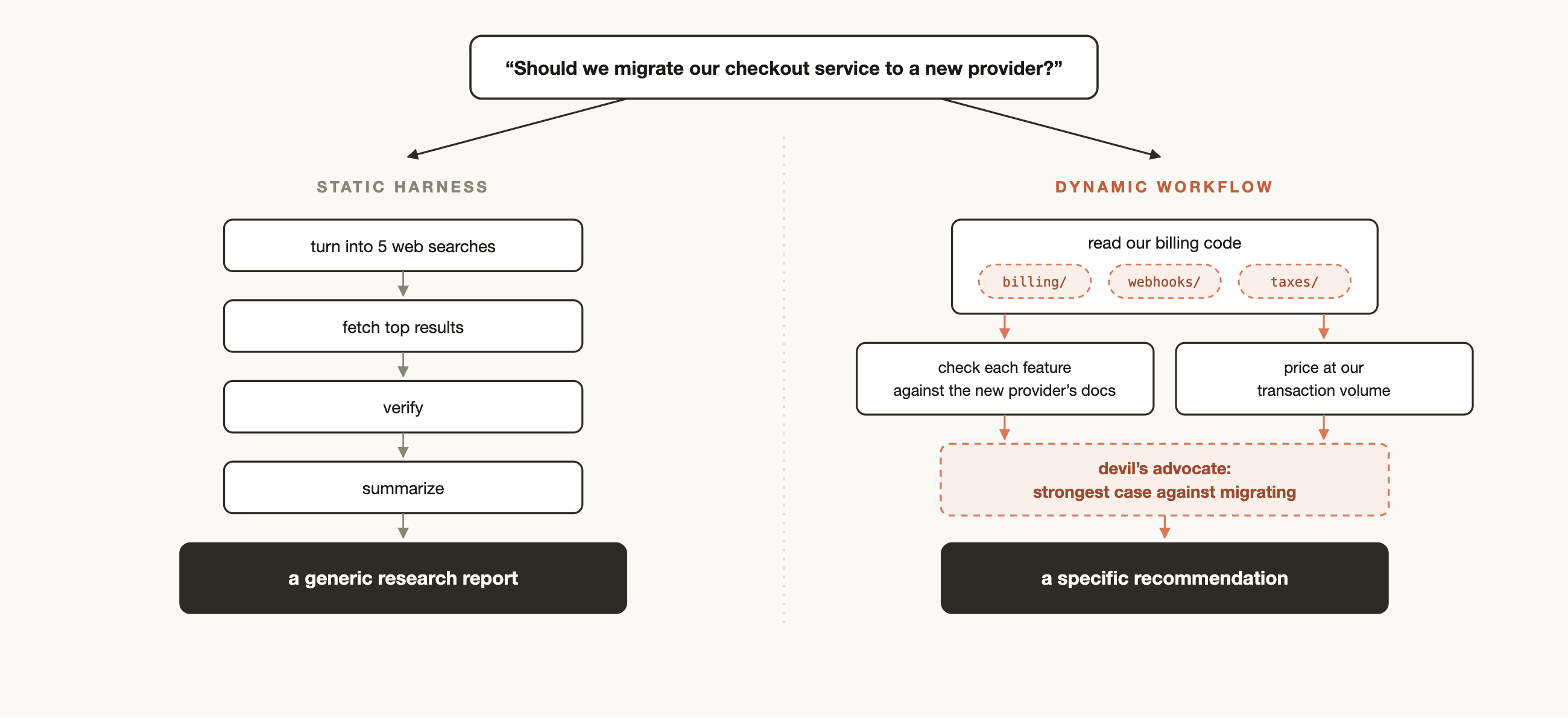
예전에도 여러 Claude 인스턴스를 엮는 정적 워크플로우는 만들 수 있었다. 하지만 정적 워크플로우는 늘 일반화의 부담을 진다. 모든 예외를 미리 생각해야 하고, 그래서 구조가 둔해진다.
동적 워크플로우의 재미는 반대 방향에 있다. 작업을 받은 뒤 그 작업에 맞는 하네스를 그 자리에서 짠다. “체크아웃 서비스를 새 결제 사업자로 옮겨야 하나?”라는 질문이라면, 단순 웹 검색 보고서가 아니라 기존 과금 코드 읽기, 마이그레이션 위험 검토, 가격 계산, 추천안 작성까지 이어지는 구조를 만들 수 있다.
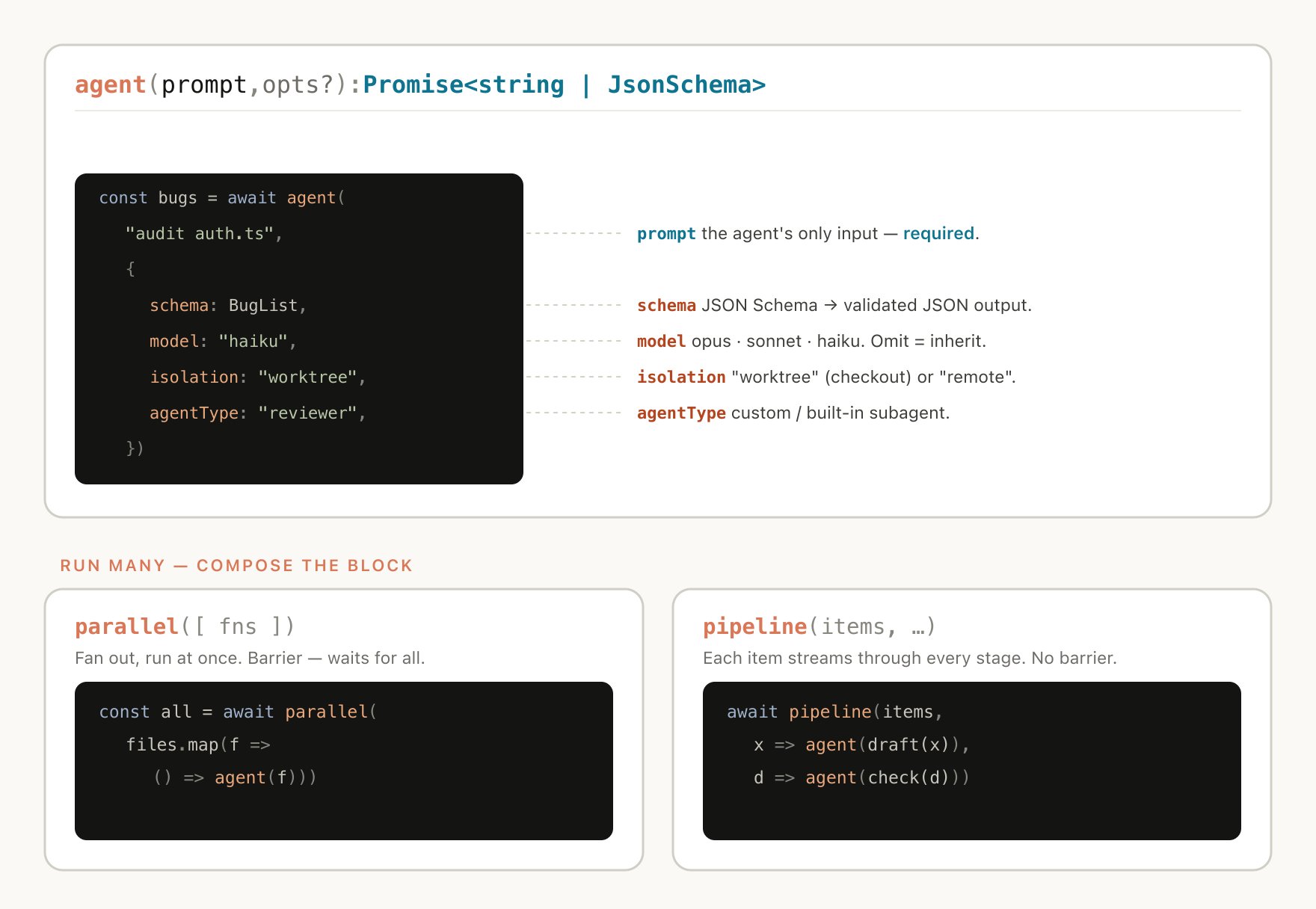
이건 코드를 에이전트 하네스로 다루는 관점과도 맞닿아 있다. 프롬프트가 “말”이라면 워크플로우는 “작업장”이다. 모델에게 부탁하는 수준을 넘어, 모델이 실수하기 어려운 작업장을 깔아주는 쪽에 가깝다.
자주 쓰이는 여섯 가지 패턴
Anthropic 글에서 특히 유용하게 정리한 부분은 패턴이다. 동적 워크플로우는 아무렇게나 에이전트를 많이 띄우는 기능이 아니다. 반복해서 등장하는 구조가 있다.
분류하고 행동하기. 여러 갈래로 흩뿌린 뒤 합성하기. 결과물을 적대적으로 검증하기. 아이디어를 많이 만든 뒤 걸러내기. 여러 해법을 토너먼트로 겨루게 하기. 그리고 새 발견이 없어질 때까지 반복하기.
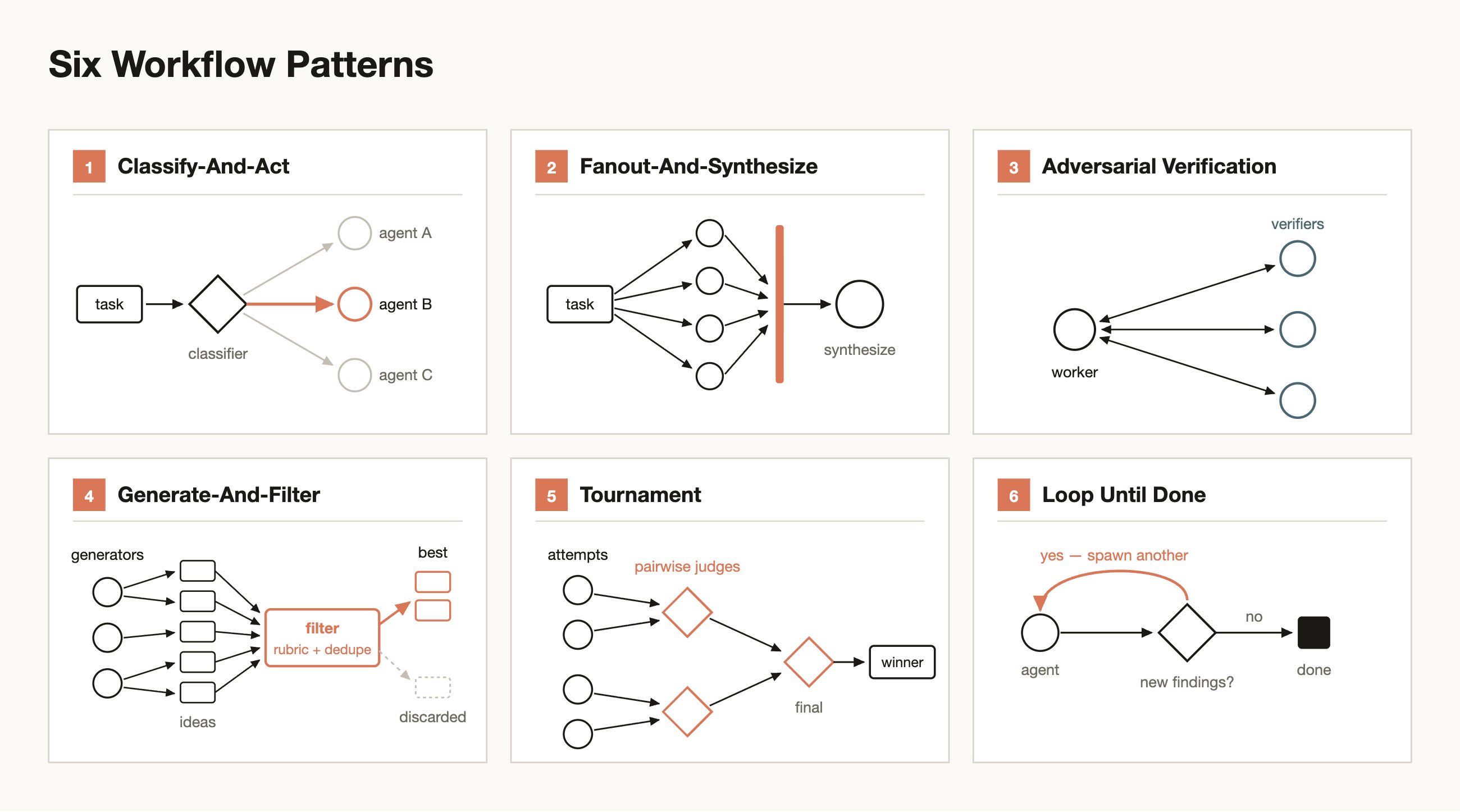
여기서 중요한 건 병렬성보다 분리된 맥락이다. 각 하위 에이전트가 자기 일만 본다. 검증자는 생성자의 생각을 공유하지 않는다. 합성자는 모든 결과가 들어온 뒤에야 판단한다. 그래서 한 컨텍스트 안에서 생기는 자기확신을 구조적으로 줄일 수 있다.
빛나는 작업은 따로 있다
동적 워크플로우가 모든 작업에 필요한 건 아니다. 버튼 이름 하나 바꾸는 일에 리뷰어 다섯 명을 붙이는 건 과하다. 하지만 다음 종류의 작업에서는 이야기가 달라진다.
마이그레이션과 리팩터링. 조사와 리포트. 사실 검증. 대량 분류. 루브릭 기반 평가. 규칙 준수 확인. 원인 분석. 백로그 트리아지. 취향이 들어가는 탐색. 모델 라우팅.
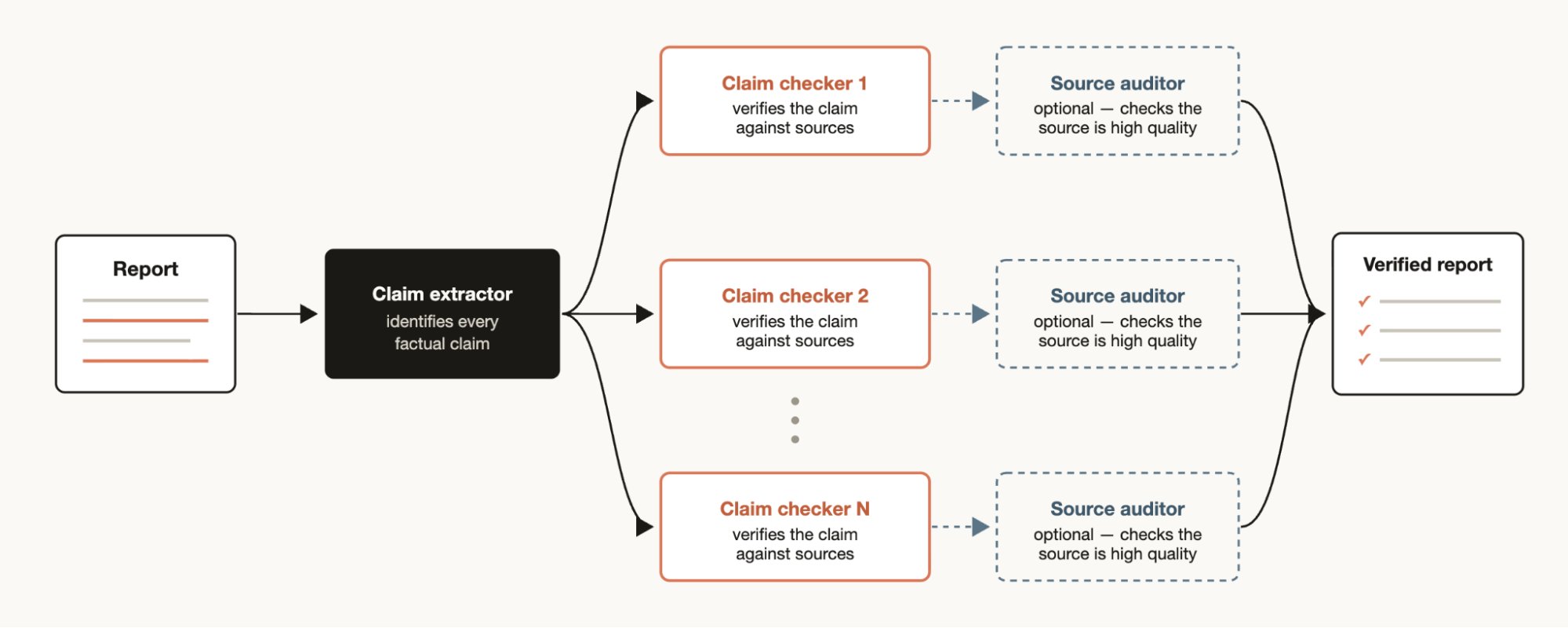
예를 들어 연구 리포트라면 먼저 주장을 뽑아내고, 주장마다 별도의 에이전트가 근거를 찾고, 또 다른 에이전트가 그 근거의 품질을 의심하게 만들 수 있다. 이 구조는 사람이 좋은 리서치팀을 꾸릴 때와 닮았다. 조사자와 검토자를 같은 사람에게 맡기지 않는 것이다.
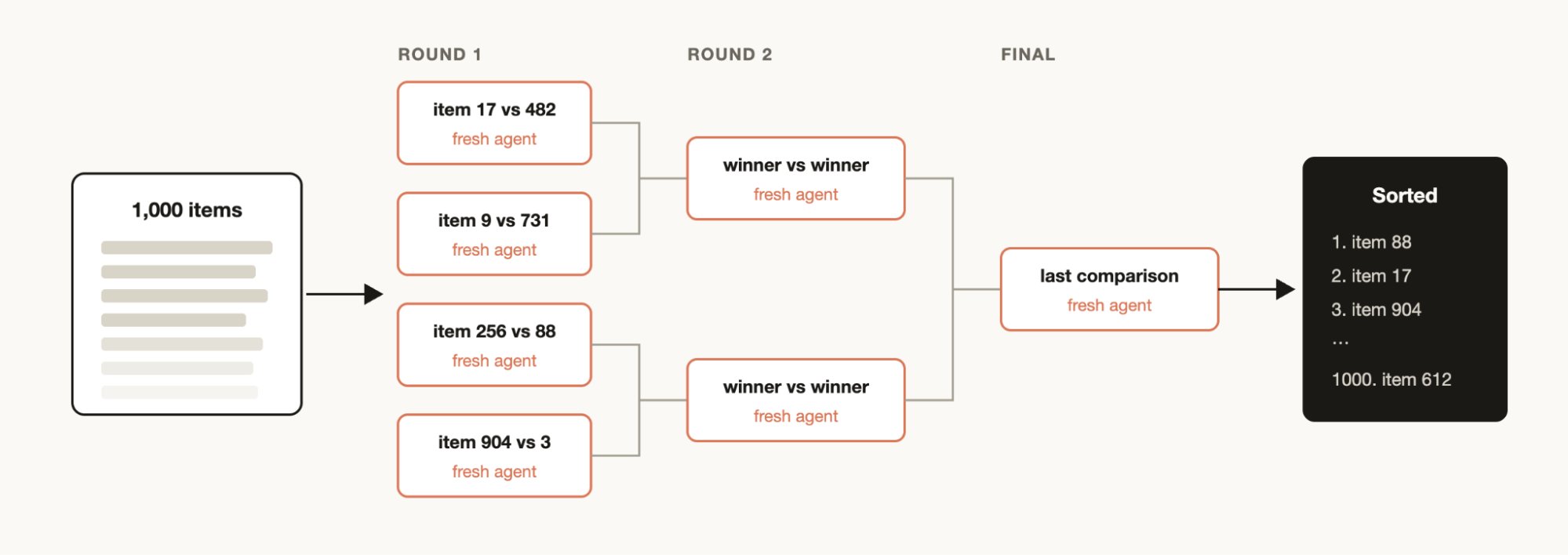
대량 정렬은 점수가 아니라 비교로 풀린다
1,000개 티켓을 심각도순으로 정렬하라고 하면 모델은 쉽게 지친다. 절대 점수도 흔들린다. 워크플로우는 이 문제를 토너먼트나 쌍대 비교(pairwise comparison)로 바꿀 수 있다.
두 항목씩 비교하게 하면 판단이 쉬워진다. 여러 에이전트가 작은 비교를 맡고, 바깥의 결정적 루프가 결과를 합친다. 모델은 “전체를 기억하는 존재”가 아니라 “작은 판단을 반복하는 부품”이 된다.
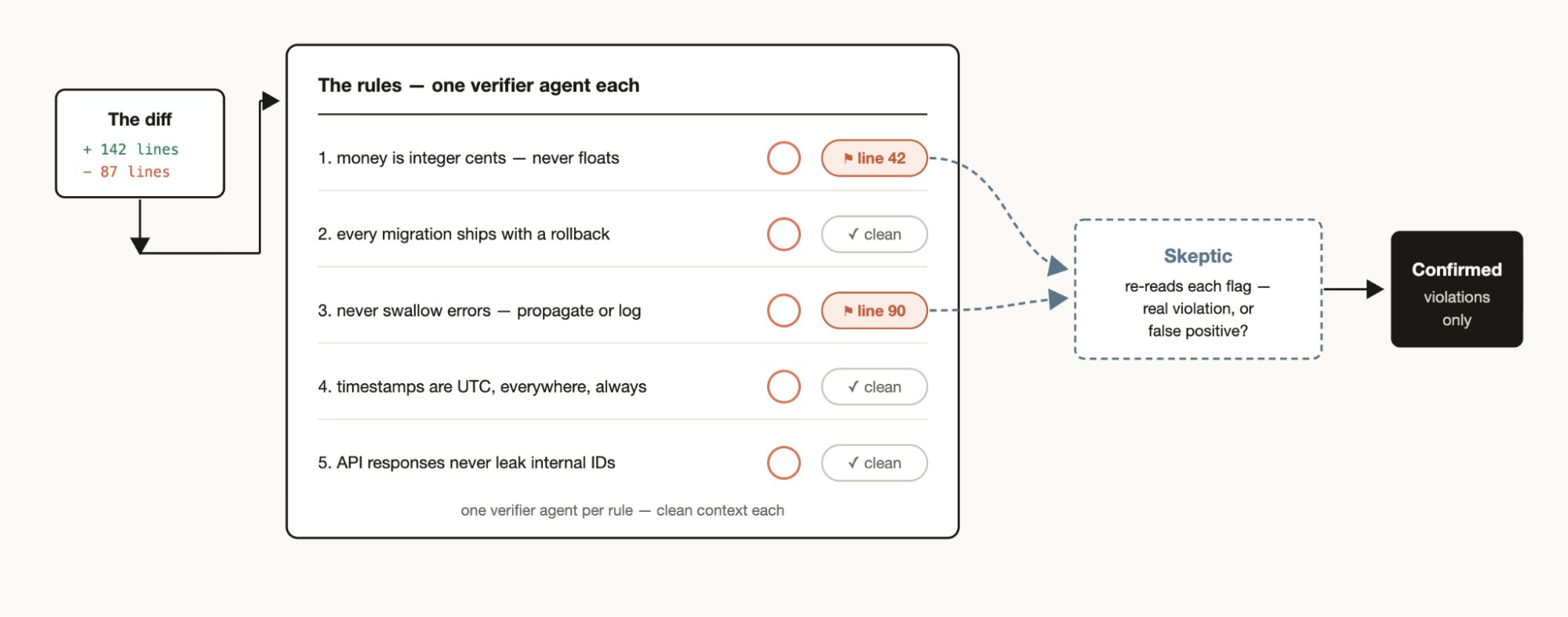
규칙 준수는 기억보다 검증자로 잡는다
Claude가 CLAUDE.md에 적어둔 규칙을 자꾸 놓친다면, 더 길게 쓰는 것만 답은 아니다. 규칙 하나마다 전담 검증자를 붙일 수 있다. “마이그레이션은 항상 롤백 경로가 있어야 한다”, “타임스탬프는 UTC로 저장한다” 같은 규칙을 각 검증자가 따로 확인하게 하는 식이다.
흥미로운 건 반대 방향도 가능하다는 점이다. 최근 세션과 코드 리뷰에서 사용자가 반복해서 고친 내용을 모으고, 후보 규칙을 만들고, 실제 실수를 막았을 규칙만 살아남게 한 뒤, 다시 CLAUDE.md로 증류할 수 있다.
트리아지는 권한 분리가 핵심이다
지원 티켓, 버그 리포트, 공개 입력을 다루는 워크플로우에는 또 다른 문제가 있다. 입력이 믿을 수 없다는 점이다. 이때는 격리(quarantine)가 필요하다.
공개 콘텐츠를 읽는 에이전트에게 높은 권한을 주지 않는다. 그 에이전트는 분류와 요약만 한다. 실제 수정, 중복 이슈 닫기, 사람에게 에스컬레이션 같은 행동은 신뢰된 에이전트가 구조화된 요약만 보고 수행한다.
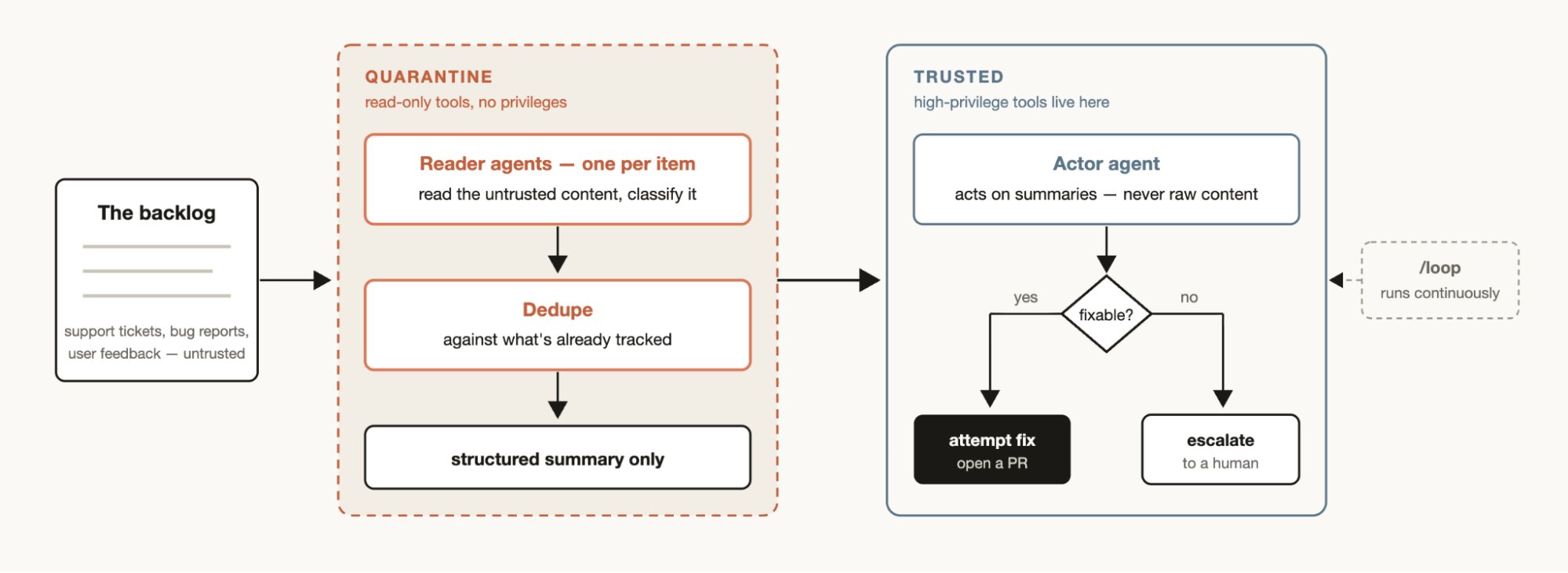
이 대목은 꽤 중요하다. 워크플로우가 강력해질수록 안전 설계도 같이 들어가야 한다. “에이전트를 많이 띄운다”가 아니라 “어떤 에이전트가 무엇을 볼 수 있고, 무엇을 할 수 있는가”를 명시하는 쪽으로 가야 한다.
저장하고 공유하면 스킬이 된다
동적 워크플로우는 일회성으로 끝낼 수도 있지만, 반복되는 작업은 저장해서 공유할 수 있다. Claude Code의 워크플로우 메뉴에서 저장하고, ~/.claude/workflows에 두거나, 스킬 폴더 안에 JavaScript 워크플로우 파일을 넣어 배포하는 방식이다.
스킬로 공유할 때 핵심은 “이 스크립트를 항상 그대로 실행하라”가 아니다. 더 좋은 방식은 워크플로우를 템플릿처럼 제공하는 것이다. Claude가 현재 작업에 맞게 구조를 조정하되, 이미 검증된 패턴을 출발점으로 삼게 한다.

이 기능의 진짜 이름은 성실함을 자동화하는 구조다
동적 워크플로우를 “에이전트 병렬 실행 기능”으로만 보면 절반만 본 것이다. 핵심은 성실함을 모델의 기분에 맡기지 않는 데 있다. 끝까지 했는가. 반박을 받았는가. 기준을 지켰는가. 멈춰도 되는 조건을 만족했는가.
좋은 프롬프트는 모델에게 더 잘 말하게 만든다. 좋은 워크플로우는 모델이 덜 속고, 덜 빼먹고, 덜 자기편을 들게 만든다. 앞으로의 에이전트 작업은 “무슨 말을 시킬까”보다 “어떤 구조 안에서 일하게 할까”에 더 가까워질 것이다.
출처: Thariq Shihipar의 X 게시물, Anthropic Claude Blog - A harness for every task: dynamic workflows in Claude Code