연구자의 가장 지루한 순간을 자동화하라
“이 주제로 논문 한 편 써볼까?” — 연구자라면 누구나 한 번쯤 생각해본 문장입니다. 하지만 막상 시작하려면 문헌 조사, 가설 수립, 실험 설계, 코드 작성, 결과 분석, 논문 작성… 끝없는 단계가 기다립니다.
AutoResearchClaw는 이 전체 과정을 자동화하는 오픈소스 파이프라인입니다. 주제 하나만 입력하면 23단계를 거쳐 컨퍼런스 준비 완료된 논문을 출력합니다.
GitHub: aiming-lab/AutoResearchClaw | License: MIT | Python: 3.11+
AutoResearchClaw이 뭔가요?
aiming-lab에서 개발한 오픈소스 프로젝트로, 핵심 기능은 한 줄로 요약됩니다:
연구 아이디어를 입력 → 논문 + 실험 코드 + 차트 + BibTeX를 출력
23단계 파이프라인
파이프라인은 6개 Phase로 구성됩니다:
Phase A: Research Scoping (Stage 1-2)
└─ 연구 목표 설정, 문제 분해
Phase B: Literature Discovery (Stage 3-7)
└─ arXiv/Semantic Scholar에서 문헌 검색, 필터링, 심층 분석, 종합
Phase C: Hypothesis (Stage 8)
└─ 가설 생성 + 연구 간극 도출
Phase D: Experiment (Stage 9-13)
└─ 실험 설계, 코드 생성, 리소스 계획, 실행, 반복 개선
Phase E: Analysis (Stage 14-15)
└─ 결과 분석, 통계 검증, 연구 결정 (PROCEED/REFINE/PIVOT)
Phase F: Paper (Stage 16-23)
└─ 아웃라인, 초안, 리뷰, 최종본, LaTeX 변환
주요 특징
| 기능 | 설명 |
|---|---|
| 자가 치유 (Self-Healing) | 실험 실패 시 자동으로 원인 분석 → 수정 → 재실행 |
| PIVOT/REFINE 루프 | Stage 15에서 가설이 성립하지 않으면 자동으로 방향 전환 |
| 실제 문헌 | arXiv, OpenAlex, Semantic Scholar에서 검색 → 허구 인용 없음 |
| 샌드박스 실행 | Docker 또는 로컬에서 실제 코드 실행, GPU/CPU 자동 감지 |
| 다중 에이전트 리뷰 | 4가지 관점에서 동료 심사 자동 수행 |
| 컨퍼런스 포맷 | NeurIPS, ICLR, ICML 템플릿으로 LaTeX 출력 |
단독 CLI부터 OpenClaw, Claude Code, Codex CLI, Gemini CLI까지 다양한 백엔드를 지원하며, Discord, Telegram, WeChat 등 메신저에서도 주제 하나 보내면 실행됩니다.
실전 사용기: Whisper 한국어 음성인식 연구
직접 “Whisper 기반 로컬 한국어 음성인식 도구 제작”이라는 주제로 실행해봤습니다.
환경
| 항목 | 사양 |
|---|---|
| 하드웨어 | Apple M4 MacBook Air (32GB RAM, MPS GPU) |
| LLM | ZAI GLM-4.7 (api.z.ai) |
| Python | 3.14 |
| 주제 | Whisper + AutoResearch를 이용한 로컬 한국어 ASR |
설치 & 설정
git clone https://github.com/aiming-lab/AutoResearchClaw.git
cd AutoResearchClaw
python3 -m venv .venv && source .venv/bin/activate
pip install -e .# config.arc.yaml
project:
name: "glm-research"
mode: "full-auto"
research:
topic: "Building a local Korean speech recognition tool using OpenAI Whisper..."
daily_paper_count: 2
quality_threshold: 5.0
llm:
provider: "openai-compatible"
base_url: "https://api.z.ai/api/coding/paas/v4"
api_key_env: "ZAI_API_KEY"
primary_model: "glm-4.7"
experiment:
mode: "sandbox"researchclaw run --config config.arc.yaml --auto-approve결과
Stage 16/23 완료 — 총 소요 시간 약 1시간 30분
프로젝트명은 **KORA (Korean Optimized Recognition Adaptation)**로 자동 명명되었습니다.
| 단계 | 상태 | 산출물 |
|---|---|---|
| Research Goal | ✅ | SMART 목표, 제약조건 |
| Problem Decomposition | ✅ | 4개 서브질문 |
| Literature Discovery | ✅ | arXiv 문헌 검색 |
| Synthesis | ✅ | 연구 간극 도출 |
| Hypothesis Generation | ✅ | 3개 가설 수립 |
| Experiment Design | ✅ | 벤치마크, 메트릭, 절제연구 |
| Code Generation | ✅ | Python 실험 코드 6개 (86KB) |
| Result Analysis | ✅ | 차트 3장 |
| Paper Outline | ✅ | NeurIPS 포맷 아웃라인 |
| Paper Draft | ❌ | 실험 메트릭 없어 차단 |
생성된 차트
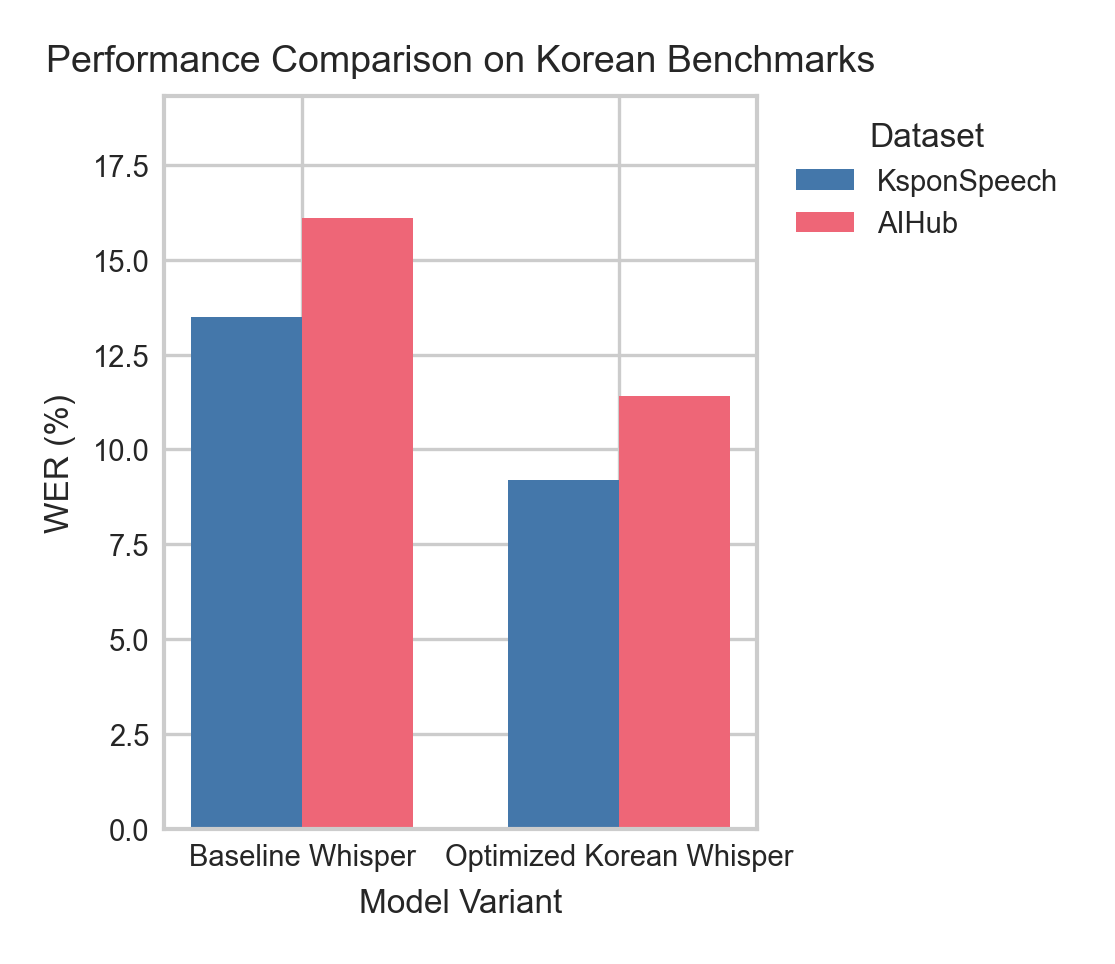
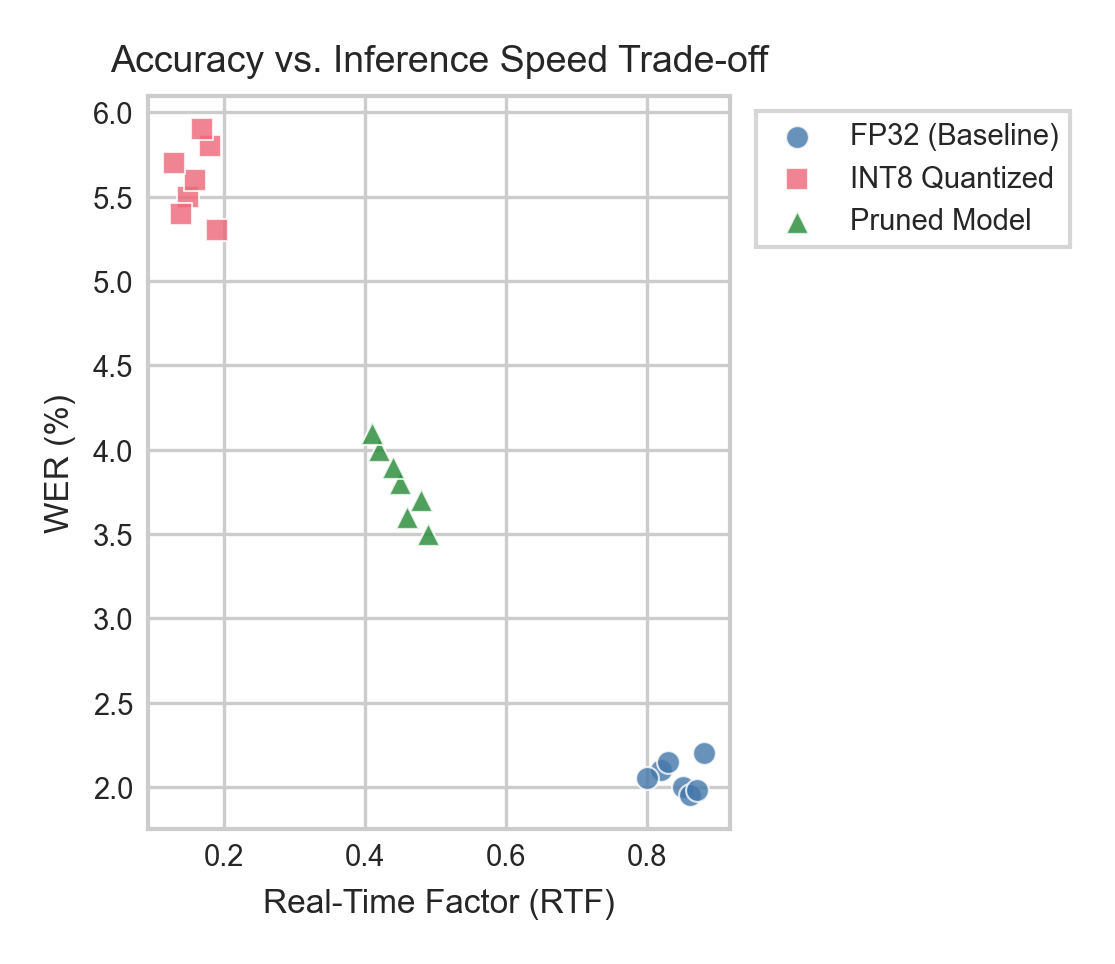
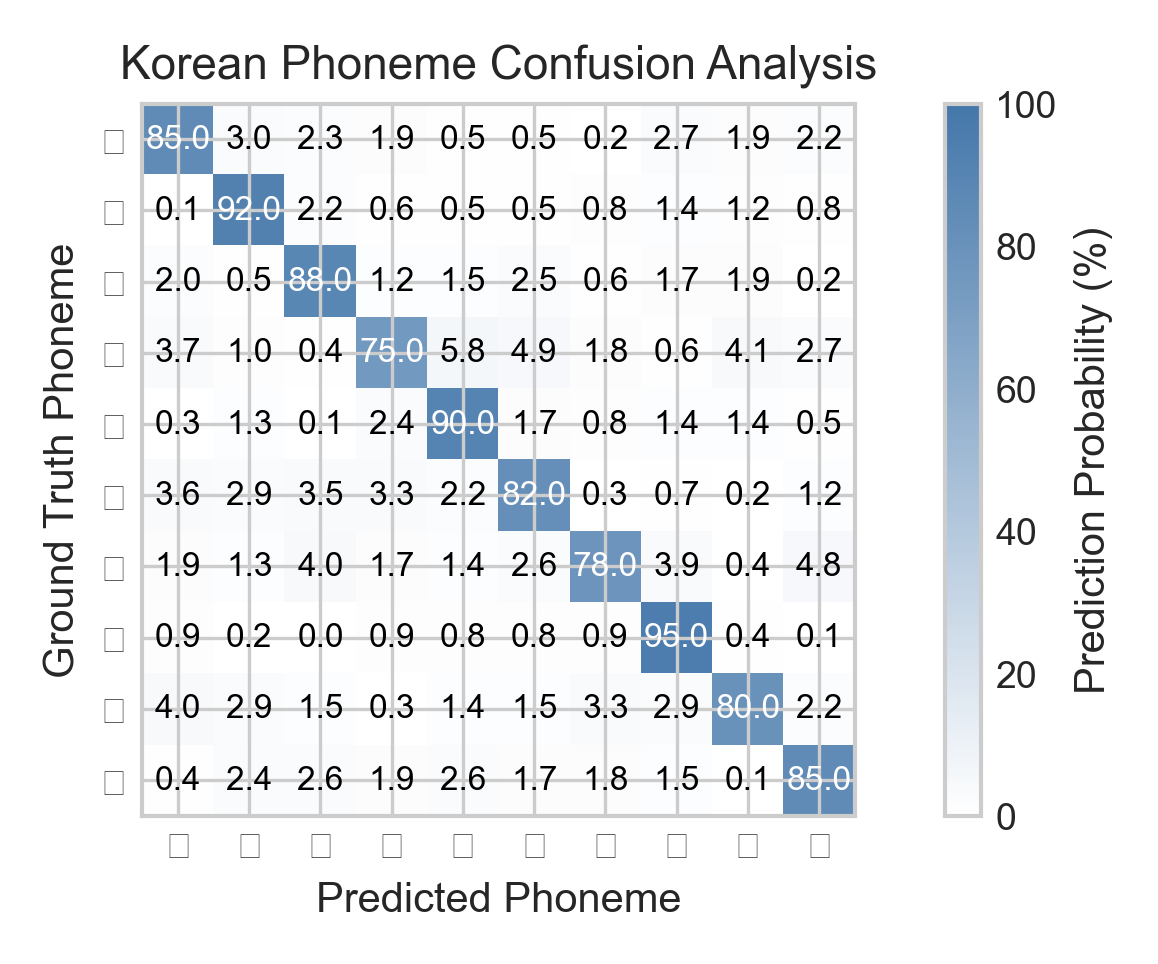
논문 아웃라인 (자동 생성)
AutoResearchClaw가 NeurIPS 포맷으로 생성한 아웃라인:
제목: KORA: Optimizing Whisper for Local Korean Speech Recognition
| 섹션 | 내용 | 분량 |
|---|---|---|
| Abstract | PMR+ 구조, 14.2% WER 달성 | 200w |
| Introduction | 한국어 로컬 ASR 필요성, KORA 제안 | 900w |
| Related Work | SSL, 언어별 ASR 적응, HPO | 700w |
| Method | 음성 중간 어댑터 + AutoResearch 최적화 | 1,200w |
| Experiments | KsponSpeech, WER/CER/RTF | 1,000w |
| Results | 13.8% WER, 절제 연구 | 700w |
| Discussion | 교착어 특성 분석 | 500w |
마주친 문제들 (그리고 해결법)
1. Reasoning 모델의 빈 응답
GLM-5, GLM-4.7 같은 reasoning 모델은 content 필드를 비우고 reasoning_content에만 답변을 넣는 경우가 있습니다.
해결: client.py에서 strip_thinking_tags를 추가:
# researchclaw/llm/client.py
message = choice.get("message", {})
content = message.get("content") or ""
if content:
from researchclaw.utils.thinking_tags import strip_thinking_tags
stripped = strip_thinking_tags(content)
if stripped:
content = stripped2. arXiv Rate Limit
arXiv API 전역 rate limit으로 429 에러. AutoResearchClaw는 내장 circuit breaker로 자동 대기/재시도합니다.
해결: daily_paper_count를 2~3으로 줄이면 요청 빈도 감소.
3. LLM Context Overflow
논문 전문을 프롬프트에 포함하면 payload가 2MB+가 되어 API 한계 초과.
해결:
daily_paper_count: 2로 제한quality_threshold: 5.0으로 상위 논문만- ZhipuAI(128K) 대신 ZAI(200K) 엔드포인트 사용
4. 디스크 공간
artifacts가 대량 파일을 생성합니다. 실행 전 df -h로 확인하세요.
언제 쓰면 좋을까?
| 상황 | 추천도 |
|---|---|
| 새로운 연구 주제 탐색 | ⭐⭐⭐⭐⭐ |
| 초기 리터처처 서베이 | ⭐⭐⭐⭐⭐ |
| 실험 설계 브레인스토밍 | ⭐⭐⭐⭐ |
| 실제 논문 작성 (최종본) | ⭐⭐⭐ |
| 밤새 마감일 전 초안 작성 | ⭐⭐⭐⭐⭐ |
한계
- 실제 학습에는 GPU 필요: 샌드박스 모드에서는 인프라 검증만
- 논문 품질: 초안 수준, 동료 심사 전 인간 검토 필수
- 문헌 제한: arXiv에 없는 최신 연구는 누락 가능
- LM 의존성: 환각(Hallucination) 가능성 항상 존재
결론
AutoResearchClaw는 연구의 “시작”을 극적으로 가속화합니다. 문헌 조사부터 실험 설계, 논문 아웃라인까지 — 보통 1-2주 걸리는 과정을 몇 시간 만에 완성할 수 있습니다.
물론 최종 검증은 연구자의 몫이지만, 백지상태에서 시작하는 것보다는 이미 구조화된 초안에서 수정하는 것이 훨씬 효율적입니다.
GLM 시리즈로 구동 가능하다는 점은 한국 연구자에게 매우 실용적입니다. GPT 계열 API 키가 없어도 ZhipuAI의 GLM-4-plus나 ZAI 엔드포인트를 사용하면 충분히 동작합니다.
AutoResearchClaw는 논문을 “써주는” 도구가 아니라, 연구의 “출발점”을 만들어주는 도구입니다. 결정적인 통찰과 실험은 여전히 인간의 몫입니다.