한 줄 요약
LLM-as-Code는 에이전트의 제어 흐름을 LLM에서 코드로 옮기는 패러다임 전환을 제안한다. ReAct 루프 기반의 기존 프레임워크(AutoGen, OpenHands, MetaGPT 등)가 안고 있는 토큰 폭발, 제어 흐름 환각, 불안정한 완료라는 세 가지 고질병은 구현 버그가 아니라 “확률적 시스템에 결정론적 작업을 맡긴” 구조적 결과다. 프로그램이 루프·분기·순차 실행을 관장하고, LLM은 추론이 필요한 순간에만 함수처럼 호출된다. OSWorld 벤치마크에서 기존 최고 시스템(80.4점, 100단계)을 **86.8점(15단계)**으로 능가하며 이 설계가 실용적임을 입증했다.
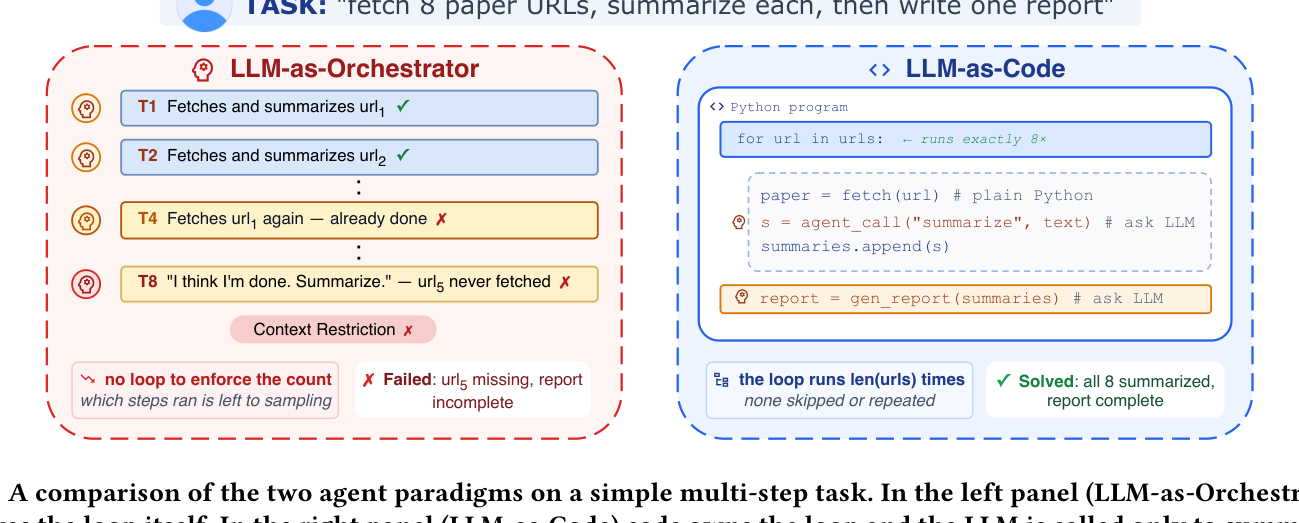 Figure 1: LLM-as-Orchestrator(좌) vs LLM-as-Code(우). 8개 URL을 처리하는 단순 작업에서, 좌측은 LLM이 직접 루프를 돌리며 URL1을 재호출하고 URL5를 누락한 채 조기 종료한다. 우측은 for 루프가 각 URL을 정확히 한 번씩 처리하고 LLM은 요약·보고서 작성에만 사용된다.
Figure 1: LLM-as-Orchestrator(좌) vs LLM-as-Code(우). 8개 URL을 처리하는 단순 작업에서, 좌측은 LLM이 직접 루프를 돌리며 URL1을 재호출하고 URL5를 누락한 채 조기 종료한다. 우측은 for 루프가 각 URL을 정확히 한 번씩 처리하고 LLM은 요약·보고서 작성에만 사용된다.
문제: 왜 LLM 오케스트레이터는 실패하는가?
현재几乎所有 주류 에이전트 프레임워크는 LLM을 “오케스트레이터”로 배치한다. 모델이 다음 단계를 결정하고, 도구를 호출하고, 언제 끝낼지 판단한다. 이 ReAct 루프는 짧은 데모에서는 매력적이지만, 장기 과업(multi-file 리팩터링 등)에 들어가면 세 가지 치명적 증상이 반복된다.
1. 토큰 폭발 (Token Explosion)
매 단계마다 컨텍스트가 누적되어 윈도우가 가득 차면, 초반의 원인 분석이 잘려나간다. 더 긴 컨텍스트 윈도우는 비용과 지연만 키울 뿐, 리콜은 윈도우가 다 채워지기 전에 이미 감소한다.
2. 제어 흐름 환각 (Control-Flow Hallucination)
검증기가 돌기도 전에 “이슈 해결됨”이라고 보고하거나, 존재하지 않는 단계를 실행한다. LLM이 “다음에 무엇을 할지”를 샘플링하는 것은 확률 분포에서 제어 흐름 간선을 뽑는 것과 같다. per-step 정확도가 1 미만이면, 과업이 길어질수록 완전 정답 확률이 지수적으로 감소한다.
3. 불안정한 완료 (Unreliable Completion)
최근 실패한 테스트에 휘둘려 올바른 이전 진단을 포기한다. 해야 할 단계가 실제로 실행되었음을 보장하는 메커니즘이 없다.
핵심 통찰: 더 좋은 프롬프트, 더 긴 컨텍스트, 더 똑똑한 재시도 로직은 각 증상의 실패 확률을 낮출 뿐, 구조적으로 제거하지는 못한다. 충분히 긴 과업에서는 반드시 실패가 누적된다.
해법: Agentic Programming의 4가지 설계 원칙
논문이 제안하는 LLM-as-Code 패러다임은 다음 네 가지 요소로 구성된다:
(1) 코드 기반 워크플로우 (Code-Driven Workflow)
루프, 분기, 순차 실행을 프로그램이 담당한다. for 루프는 정확히 n번 실행되고, if 분기는 조건이 참일 때만 선택된다. LLM은 요약, 코드 생성, 판단이 필요한 결정점에서만 호출된다. 모델이 프로그램의 실행 경로를 바꿀 수 없다.
(2) DAG 구조 컨텍스트 (DAG-Structured Context)
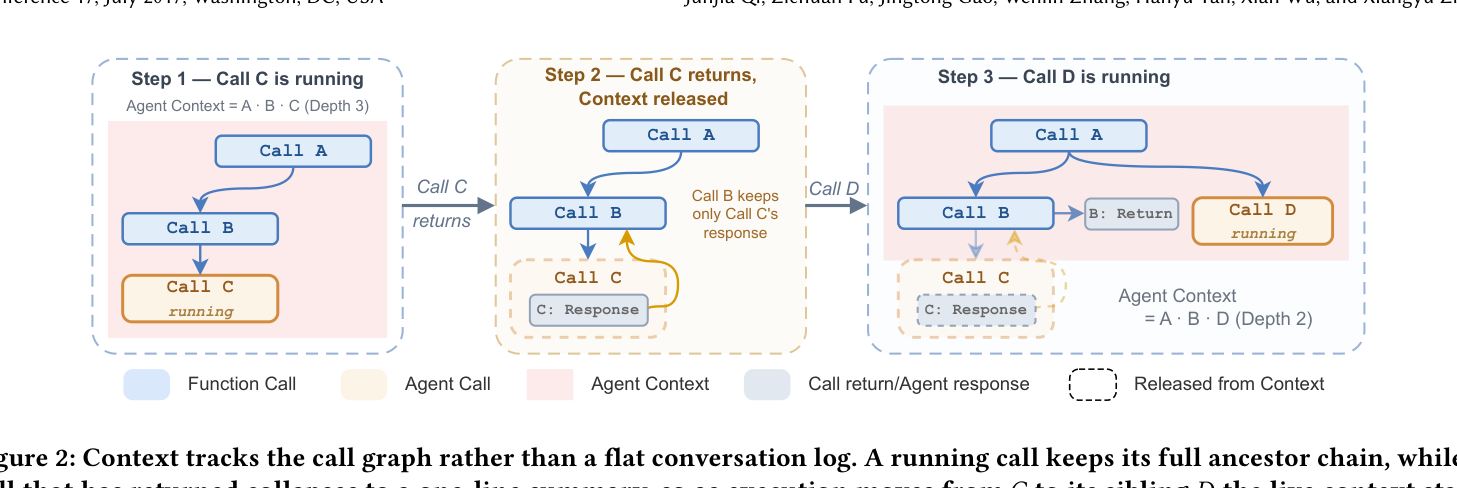 Figure 2: LLM-as-Orchestrator는 매 단계마다 대화 기록이 누적되어 컨텍스트가 선형 증가한다. LLM-as-Code는 호출 그래프(call graph)가 DAG를 이루며, 각 호출의 컨텍스트 길이가 누적이 아닌 호출 깊이(call depth)에 의해 결정된다.
Figure 2: LLM-as-Orchestrator는 매 단계마다 대화 기록이 누적되어 컨텍스트가 선형 증가한다. LLM-as-Code는 호출 그래프(call graph)가 DAG를 이루며, 각 호출의 컨텍스트 길이가 누적이 아닌 호출 깊이(call depth)에 의해 결정된다.
실행 히스토리가 평면 대화 로그가 아니라 **호출 그래프(call graph)**가 된다. 각 함수 호출은 자신의 조상 체인 전체의 컨텍스트에 접근하지만, 형제 노드의 컨텍스트는 이미 반환된 요약만 본다. 컨텍스트 길이가 단계 누적이 아니라 호출 깊이에 비례하므로, 100단계 작업에서도 컨텍스트가 통제된다.
(3) 자연스러운 멀티 에이전트 (Multi-Agent for Free)
에이전트 함수를 여러 개 호출하면, 프로그램이 일반 코드처럼 병렬 실행한다. DAG 컨텍스트가 그대로 적용되어, 각 에이전트는 자신의 호출 경로에만 스코프를 가진다. 별도의 “슈퍼바이저 모델”이 조율하지 않아도 그래프 자체가 조정 메커니즘이 된다.
(4) 자가 프로그래밍 진화 (Self-Programmed Evolution)
에이전트가 개선 사항을 코드로 커밋한다. 학습된 개선이 프롬프트가 아닌 durable code로 남아, 다음 실행에서 보장된다.
검증: OSWorld 벤치마크 결과
이 설계가 실용적인지 입증하기 위해, 논문은 컴퓨터 사용 에이전트(GUI agent) 케이스 스터디를 제시한다. OSWorld 벤치마크에서:
| 시스템 | 점수 | 단계 수 |
|---|---|---|
| 기존 최고 시스템 | 80.4 | 100 |
| LLM-as-Code 에이전트 | 86.8 | 15 |
결정론적 루프가 필수 단계를 정확한 순서로 실행하므로, 샘플링된 결정이 단계를 건너뛰거나 반복하거나 순서를 바꾸는 일이 원천 차단된다. 더 적은 단계로 더 높은 점수를 달성한 것은 신뢰성이 구조에 의해 보장되기 때문이다.
시사점과 한계
에이전트 설계 패러다임의 전환
이 논문의 메시지는 단순하다: 구조가 알려진 워크플로우라면, 그 구조를 코드로 작성하라. 모델에게 위임하지 마라. LLM의 추론 능력은 컨텍스트 이해·요약·코드 생성·판단 등 비결정론적 영역에서 발휘되어야 하며, for/if/function으로 완벽히 해결되는 영역까지 확장될 필요가 없다.
적용 범위의 한계
논문 스스로 밝히는 한계: 구조가 알려지지 않은 탐색적 과업(브레인스토밍, 자유 연구 등)에서는 LLM 주도 오케스트레이션이 여전히 유효하다. LLM-as-Code의 주장은 “구조가 존재하는 작업에서는 그 구조를 코드로 작성하라”는 좁은 범위에 국한된다.
실무적 시사점
- 에이전트 프레임워크 선택 시: 단순 ReAct 루프 기반 프레임워크보다, 코드 기반 워크플로우를 지원하는 프레임워크를 우선 고려할 것
- 프롬프트 엔지니어링의 한계 인식: 규칙이 20개가 넘는 복잡한 워크플로우에서는 프롬프트로 규칙을 전달하지 말고, 코드로 구현할 것
- 컨텍스트 관리: DAG 기반 컨텍스트 구조는 장기 과업에서 비용과 성능을 동시에 개선하는 실용적 접근법
마무리
LLM-as-Code는 “더 강한 모델, 더 좋은 프롬프트”라는 통상적 처방이 닿을 수 없는 영역—구조적 신뢰성—을 정면으로 겨냥한다. 확률적 모델에게 결정론적 제어를 맡기는 아키텍처 자체가 문제라면, 해법도 아키텍처 수준에서 와야 한다. KDD 2026 AgenticSE 워크숍 채택이라는 학술적 검증에 더해, OSWorld에서 보여한 86.8점(15단계)이라는 실증 결과는 이 방향이 단순한 이론이 아님을 보여준다.
“for 루프가 n번 실행되는 것을 보장하는 유일한 방법은, 루프를 작성하는 것이다.”
원문: arXiv:2606.15874 · KDD 2026 Workshop on Agentic Software Engineering (AgenticSE)