한 줄 요약
**Agents’ Last Exam(ALE)**은 AI 에이전트가 “전문가가 며칠~몇 주에 걸쳐 완수하는 실제 업무”를 수행할 수 있는지 측정하는 벤치마크다. 250명 이상의 업계 전문가가 제출한 1,490개의 실제 프로젝트 과제를 13개 산업 클러스터·55개 하위 분야로 분류하고, 각 과제를 코드 기반 결정론적 평가기로 채점한다. 결과는 냉엄하다: Terminal-Bench에서 82%를 기록한 Codex + GPT-5.5조차 ALE의 가장 어려운 tier에서 0% 통과, 전체 평균도 1% 미만이다.
 Figure 1: ALE는 13개 산업 도메인·55개 하위 분야에 걸친 전문가 워크플로우를 포괄한다. (UC Berkeley)
Figure 1: ALE는 13개 산업 도메인·55개 하위 분야에 걸친 전문가 워크플로우를 포괄한다. (UC Berkeley)
왜 “또 벤치마크”가 아닌가?
AI 시스템이 올림피아드 수학, 경쟁 프로그래밍, 의사 국가고시를 클리어해도, 실제 산업 현장에서의 경제적 산출은 기대에 한참 못 미친다. ALE 논문은 이를 **“평가의 문제”**로 진단한다: 기존 벤치마크가 “실제 경제적 가치가 있는 장기 워크플로우에서의 지속적 성과 측정”을 갖추지 못했다는 것이다.
기존 벤치마크의 딜레마를 정리하면 이렇다:
| 벤치마크 유형 | 강점 | 한계 |
|---|---|---|
| Terminal-Bench | 실제 CLI 워크플로우, 결정론적 채점 | CLI만 지원; 개발자/시스템 관리자에 편중 |
| OSWorld | GUI 컴퓨터 사용 | GUI만; 짧은 과제 위주 |
| SWE-bench | 실제 GitHub 이슈 | 소프트웨어 엔지니어링만 |
| GDPval / Remote Labor | 경제적 가치가 있는 작업 | 인간 판사 필요 (비결정론적) |
| QA 벤치마크 | 채점 용이 | 워크플로우 실행이 아님 |
ALE은 실제 전문가 워크플로우 + 광범위한 산업 커버리지 + 결정론적 검증 세 가지를 동시에 달성하고자 한다.
ALE의 설계 원칙
1. 진짜 업무, 합성 아님
모든 과제는 비전문가가 만든 마이크로태스크가 아니라, 도메인 전문가가 실제로 수행했던 프로젝트에서 비롯된다. 전문가들은 전용 포털을 통해 제출하며, 각 과제는 다섯 가지 구성 요소를 명확히 해야 한다:
- 자연어 과제 설명
- 입력 파일
- 실제 사용하는 소프트웨어 (전문가 도구)
- 기대 산출물
- 평가 스펙 (결정론적 채점 기준)
거절된 과제 vs 수용된 과제 예시:
| 거절됨 (너무 단순) | 수용됨 (엔드투엔드 워크플로우) |
|---|---|
| “DaVinci에서 색상 필터 적용" | "달리는 치타를 다른 경주 영상으로 이동” (추적, 로토스코핑, 합성, 색보정) |
| “RPG 게임 설계" | "RPGMaker XP로 mota.exe 게임 재현” (검증 가능한 맵, 캐릭터 속성, 이벤트 상태) |
2. O*NET 기반 객관적 분류
ALE은 미국 노동부의 O*NET / SOC 2018 직업 분류 체계를 기반으로, 소프트웨어 매개 워크플로우가 의미 있는 비물리적 산업만을 선별해 13개 도메인, 55개 하위 분야로 구성했다.
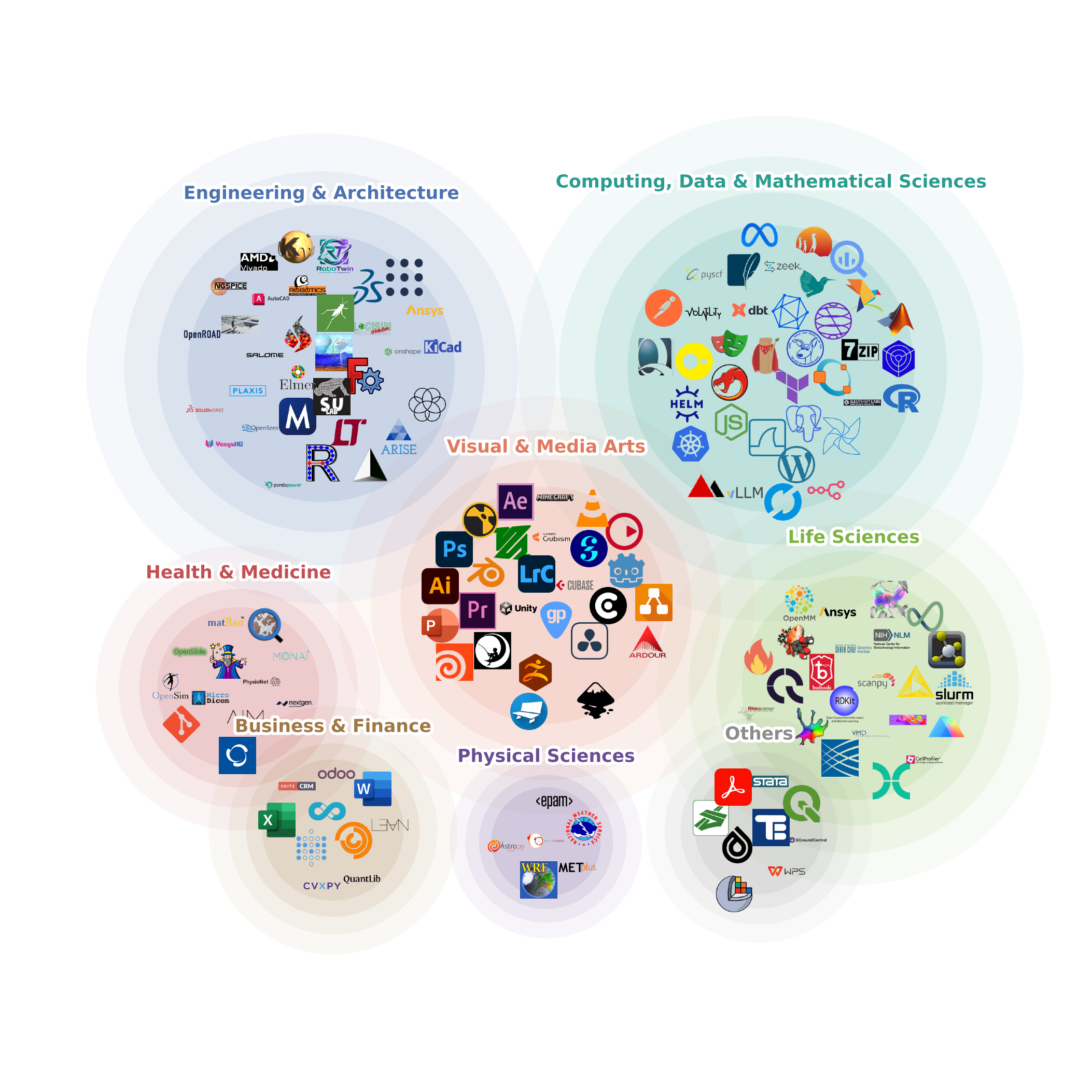 Figure 2: 1,490개 과제 인스턴스의 분포. 각 행은 55개 하위 분야 중 하나이며, 13개 최상위 도메인으로 그룹화된다. 스택 바는 완전히 구현된 인스턴스(도메인 색상)와 QC 대기 중인 전문가 제출(주황색)을 분해해서 보여준다. 55개 하위 분야 모두에 0이 아닌 커버리지가 할당되었다.
Figure 2: 1,490개 과제 인스턴스의 분포. 각 행은 55개 하위 분야 중 하나이며, 13개 최상위 도메인으로 그룹화된다. 스택 바는 완전히 구현된 인스턴스(도메인 색상)와 QC 대기 중인 전문가 제출(주황색)을 분해해서 보여준다. 55개 하위 분야 모두에 0이 아닌 커버리지가 할당되었다.
논문이 지적하는 중요한 발견: 기존 16개 주요 벤치마크를 합쳐도 55개 하위 분야 중 13개가 전혀 커버되지 않는다. ALE가 채우는 것이 바로 이 빈 자리다.
3. Generalist Computer-Use Agent (GCUA)
ALE 과제는 하나의 워크플로우 안에서 GUI 조작(데스크톱 앱, 브라우저, 전문가 도구), CLI 조작(쉘, 코드, 파일), 웹 리서치를 인터리브로 요구한다. 따라서 평가 대상은 CLI만 또는 GUI만 다루는 것이 아니라, 양쪽 모두를 포괄하는 **Generalist Computer-Use Agent(GCUA)**다.
논문은 에이전트의 역량을 5개 기능 계층으로 분해한다:
| 계층 | 기능 |
|---|---|
| Brain | LLM 추론 및 계획 |
| Eyes | 스크린샷 기반 GUI 지각 |
| Body | 오케스트레이션 및 제어 흐름 |
| Hands | 구조화된 도구 호출 |
| Feet | 런타임 기반 (액션이 작용하는 환경) |
CLI 에이전트(SWE-agent 등)는 Eyes가 없고, GUI 에이전트는 Body/Hands/Feet이 얕다. GCUA는 모든 계층에서 완전한 역량을 갖춘 에이전트를 의미한다.
평가 파이프라인
각 과제는 main.py라는 실행 가능한 스펙으로 구현되며, 세 단계 라이프사이클을 가진다:
load()— 과제 메타데이터 및 컴퓨팅 요구사항 선언start()— 원격 VM을 결정론적 시작 상태로 프로비저닝evaluate()— 에이전트의 산출물을[0, 1]점수로 채점
에이전트는 과제 설명과 메타데이터만 받고, 스크린샷·쉘 출력·마우스/키보드·파일 편집·API 호출을 통해 환경과 상호작용한다. 평가 환경은 input/(읽기 전용), software/(사전 설치 앱), output/(유일한 쓰기 가능 영역), reference/(에이전트에게 숨겨진 정답)의 4디렉토리 구조를 가진다.
결과: “1%의 벽”
가장 강력한 구성(Codex + GPT-5.5)이 ALE의 가장 쉬운 tier에서도 50% 미만, 가장 어려운 tier에서는 10% 미만에 그친다. 대부분의 주류 에이전트(Claude Code 포함)는 최하위 tier에서 0%에 가까운 통과율을 보인다.
이는 Terminal-Bench 82%와 극명한 대조를 이룬다. 에이전트가 “터미널에서 컴파일하듯 쉘 명령을 연쇄하는” 작업에는 능숙하지만, “영상 편집 소프트웨어에서 키 프레임을 추적하고, 회계 소프트웨어에서 재무제표를 작성하고, CAD에서 금형 설계를 검증하는” 작업에는 전혀 대응하지 못한다는 의미다.
시사점
-
벤치마크 포화 ≠ 실제 역량: 기존 벤치마크에서 높은 점수를 받는 것이 실제 산업 현장에서의 유용성과 직결되지 않는다. ALE은 이 격차를 정량화한다.
-
GUI + CLI 통합이 필수: 전문가 워크플로우의 대부분은 GUI 앱과 CLI 도구를 혼용한다. 어느 한쪽만 다루는 에이전트로는 55개 하위 분야의 과제를 수행할 수 없다.
-
Living benchmark 설계: ALE은 과제 풀이 지속적으로 확장되는 “살아있는 벤치마크”다. 현재 공개된 150개(약 10%)를 제외한 1,340개는 private 풀로 운영되어 데이터 오염(data contamination)을 방지한다.
-
평가 인프라의 표준화:
main.py스펙 + 4디렉토리 VM 구조는 재사용 가능한 평가 인터페이스로, 향후 다른 벤치마크에서도 차용할 수 있는 모범 사례다.
한계
- 비물리적 산업 한정: 제조 현장, 수술, 건설 등 물리적 조작이 필요한 분야는 제외되어 있다.
- 과제 구축 비용: 전문가 참여 기반 구축이므로 과제당 비용과 시간이 많이 든다.
- 현재 1,490개 과제: 산업 전체를 대표하기에는 여전히 표본이 작다. 논문도 이를 인정하며 지속적 확장을 계획하고 있다.
- 단일 에이전트 평가: 멀티 에이전트 협업 시나리오는 현재 범위 밖이다.
마무리
ALE이 던지는 질문은 단순하다: “AI 에이전트가 전문가의 실제 업무를 대체할 수 있는가?” 현재 대답은 **“아직 멀었다”**다. 하지만 이 벤치마크가 가치 있는 이유는, “얼마나 멀었는지”를 처음으로 정확하고 결정론적으로 측정해주기 때문이다. 벤치마크 성적과 GDP-수준 영향력 사이의 격차를 좁히는 첫걸음이다.
💻 프로젝트 페이지: agents-last-exam.org
📄 논문: arXiv:2606.05405