웹 브라우징 자동화는 LLM 에이전트에게 여전히 어려운 과제다. WebChallenger는 PageMem이라는 구조화된 페이지 표현을 핵심으로, 선택적 주의력·지속적 기억·절차적 숙련도라는 인간의 세 가지 인지 장점을 에이전트 아키텍처 차원에서 구현한다. 파인튜닝 없이 오픈 가중치 모델만으로 WebArena 56.3%, WorkArena 70.9%를 달성했다.
핵심 요약
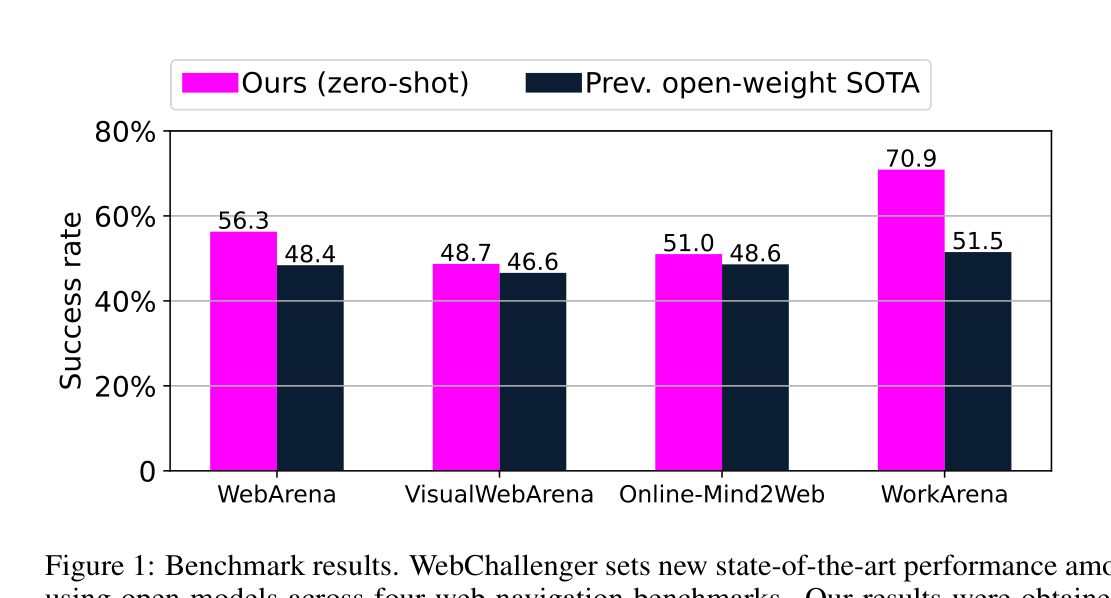
WebChallenger는 “모델 크기가 아니라 아키텍처가 웹 에이전트의 병목”이라는 가설에서 출발한다. 상용 프론티어 모델(GPT-4, Claude 등)에 의존하지 않고, 32B LLM + 7B VLM 오픈 가중치 모델 조합으로 4개 주요 웹 벤치마크에서 경쟁력 있는 성능을 달성했다.
- 문제: 기존 최고 성능 웹 에이전트는 비싼 상용 추론 모델에 의존하며, 반복적 웹 작업에 부적합
- 원인 진단: 모델 능력 부족이 아니라, 에이전트 프레임워크가 인간의 인지 장점(선택적 주의, 사이트 기억, 절차적 자동화)을 복제하지 못함
- 해결: PageMem이라는 DOM 기반 구조화 페이지 표현 위에 3가지 메커니즘(분할 정복 관측, 오프라인 사이트 탐색 기억, 복합 액션 워크플로우)을 구축
- 핵심 결과: WebArena 56.3%, VisualWebArena 48.7%, Online-Mind2Web 51.0%, WorkArena 70.9% — 오픈 모델 기반 에이전트 중 최고 수준
인간은 어떻게 웹을 탐색하는가?
저자들은 웹 탐색에서 인간이 가지는 세 가지 인지적 장점을 식별한다.
- 선택적 주의력(Selective Attention): 인간은 페이지 전체가 아닌 관련 영역만 주시한다. 반면 LLM 에이전트는 페이지 전체를 평면적인 토큰 시퀀스로 받아들이므로, 관련 정보가 불필요한 컨텍스트에 묻힌다.
- 지속적 기억(Persistent Memory): 인간은 한 번 방문한 사이트의 레이아웃과 기능을 기억한다. LLM 에이전트는 매 세션마다 환경 지식 없이 시작한다.
- 절차적 숙련도(Procedural Fluency): 인간은 검색, 드롭다운 선택, 폼 작성 같은 흔한 상호작용 패턴을 내면화하여, 각 단계를 의식적으로 추론하지 않고도 실행한다. LLM 에이전트는 매 원자적 액션마다 전체 페이지 상태를 다시 관찰하고 추론해야 한다.
Moravec의 역설이 웹 에이전트에도 그대로 나타난다. 수학과 코딩에 능한 모델이, 인간에게는 자연스러운 웹 브라우징에는 놀라울 만큼 서툴다.
PageMem: 구조화된 페이지 표현
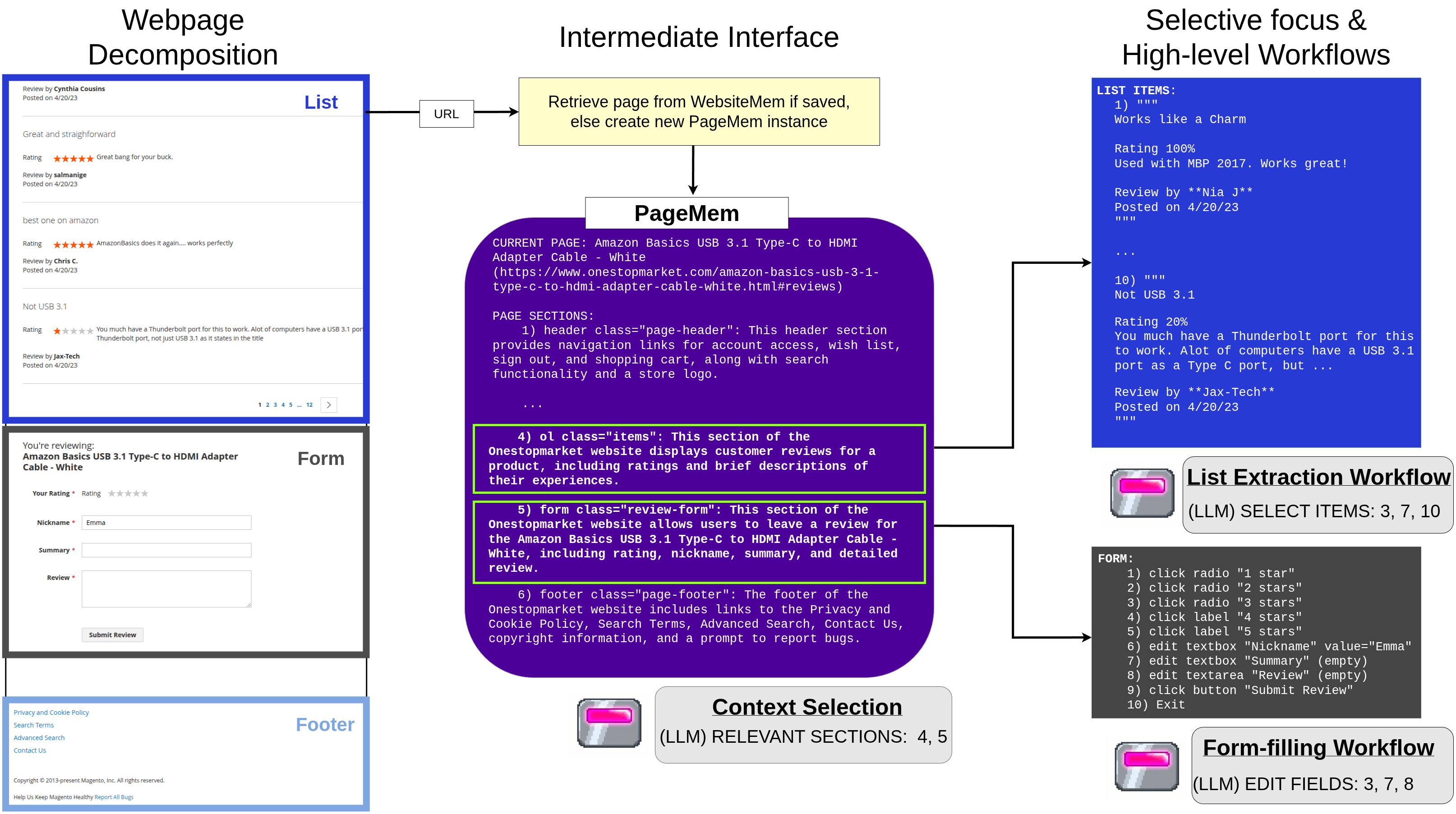
WebChallenger의 모든 것은 PageMem이라는 공통 추상화 위에 구축된다. PageMem은 DOM에서 결정론적으로 생성되는 구조화된 페이지 표현으로, 4단계 계층 구조를 가진다.
| 계층 | 설명 |
|---|---|
| WebsiteMem | 웹사이트 하나의 모든 PageMem과 요소를 포함하는 최상위 기억 |
| PageMem | 단일 페이지. 제목, URL, 섹션 목록, 페이지 요약을 보유 |
| PageSection | 페이지 내의 의미적 영역(네비게이션 바, 상품 목록, 리뷰 폼 등). DOM 속성과 LLM 생성 요약을 함께 보유 |
| Element | 개별 상호작용 위젯. 클릭 가능 요소, 현재 값, 상태 정보를 포함 |
핵심 통찰: PageMem이라는 공통 인터페이스가 있기 때문에, 관측·기억·액션의 세 가지 메커니즘이 사이트별 어댑터 없이 일관되게 동작할 수 있다.
PageMem 구성 과정
- DOM 트리를 재귀적으로 분할 → 크기 임계값 미만이거나 그룹핑 태그(form, ul, li, table, section 등)에서 종료
- 같은 태그와 클래스를 공유하는 형제 노드들을 하나의 리스트 섹션으로 그룹화
- 클릭 가능 요소를 탐지하여 조상 섹션에 할당
- LLM/VLM으로 각 섹션과 페이지 전체의 한 줄 요약 생성
세 가지 메커니즘
1. 분할 정복 관측 파이프라인
전체 페이지를 직렬화하는 대신, 3단계로 관측을 분해한다.
- 1단계 (Skim): PageMem의 섹션 요약을 훑어보고, 작업에 관련된 섹션 부분집합 선택
- 2단계 (Extract): 선택된 섹션의 전체 내용에서 작업 관련 세부정보만 추출
- 3단계 (Synthesize): 추출된 정보를 작업 중심 페이지 요약으로 종합
이렇게 하면 전체 페이지를 처리하지 않고도 정보 밀도 높은 관측을 생성할 수 있다.
2. 오프라인 사이트 탐색과 영구 기억
작업 실행 전, 결정론적 오프라인 탐색 단계가 각 웹사이트를 순회하며 WebsiteMem을 구축한다. 이는 LLM 가이드나 작업 데모 없이 자동으로 수행되며, 페이지 템플릿과 요소 동작 정보를 포함한다. 한 번 구축된 WebsiteMem은 이후 모든 작업에서 재사용된다.
3. 복합 액션 워크플로우
흔한 다단계 상호작용(검색, 드롭다운 선택, 폼 제출 등)을 단일 에이전트 액션으로 압축한다. 섹션 타입에 따라 워크플로우가 디스패치되며, 드롭다운 확장 같은 부분 상태 변화를 자동으로 처리한다. 즉, 에이전트가 매 원자적 액션마다 전체 페이지를 다시 처리할 필요가 없다.
성능: 오픈 모델로 어디까지 갈 수 있는가?
| 벤치마크 | WebChallenger | 비고 |
|---|---|---|
| WebArena | 56.3% | 오픈 모델 기반 에이전트 중 최고 |
| VisualWebArena | 48.7% | 시각+텍스트 웹 환경 |
| Online-Mind2Web | 51.0% | 실제 온라인 웹사이트 |
| WorkArena | 70.9% | 엔터프라이즈 웹 작업 |
이 결과는 32B LLM과 7B VLM, 파인튜닝 없이 달성한 것이다. 프론티어 상용 모델 기반 시스템에 근접하면서도 추론 비용은 극히 일부만 든다.
시사점
- 스캐폴딩이 모델 스케일보다 중요할 수 있다: 충분한 아키텍처 설계만으로 소형 모델의 웹 에이전트 성능을 획기적으로 끌어올릴 수 있다.
- 컨텍스트 엔지니어링의 핵심: 무엇을 모델에 보여줄 것인가를 선택하는 것이, 모델 자체의 능력보다 병목일 수 있다.
- 범용성: PageMem이라는 사이트 무관 추상화 덕분에, 사이트별 어댑터 없이도 새로운 웹사이트에 일반화된다.
- 비용 효율성: 반복적 웹 작업 자동화에 있어 비싼 상용 모델 API 호출을 대체할 수 있는 실용적 경로를 보여준다.
한계
- 오프라인 탐색 단계가 선행되어야 하므로, 완전히 미지의 사이트에는 즉시 대응하기 어려움
- 32B + 7B 모델도 여전히 로컬 실행에는 상당한 자원이 필요
- DOM 기반 접근이므로, 캔버스 기반 콘텐츠나 복잡한 동적 렌더링에 한계가 있을 수 있음