SearchSwarm: 에이전트 LLM에 ‘위임 지능’을 가르치다
긴 호라이즌의 심층 리서치 과제에서 단일 모델이 스스로 작업을 분해하고 하위 에이전트에게 위임하는 방법을 학습하는 혁신적 접근
한 줄 요약
SearchSwarm은 LLM 에이전트가 **“위임 지능(Delegation Intelligence)“**을 내재화하도록 훈련시키는 프레임워크입니다. 메인 에이전트가 장기 연구 과제를 하위 작업으로 분해하고, 독립 컨텍스트를 가진 서브에이전트에게 위임한 뒤 결과를 통합하는 방식으로, 30B 파라미터 모델이 10배 이상 큰 모델들과 경쟁하는 성능을 달성합니다.
왜 필요한가?
딥 리서치(Deep Research)와 같은 장기 에이전트 과제는 컨텍스트 윈도우 한계, 검색 효율성, 정보 통합 병목 등 여러 문제에 직면합니다. 기존 방식은:
- 단일 에이전트가 모든 작업을 직접 수행 → 컨텍스트 오버플로우
- 단순 병렬화 → 작업 간 의존성 무시, 결과 품질 저하
- 수동 파이프라인 → 유연성 부족, 새로운 과제 적응 불가
핵심 문제는 “언제, 무엇을, 어떻게 위임할 것인가”를 모델 스스로 학습해야 한다는 점이었습니다.
핵심 방법론
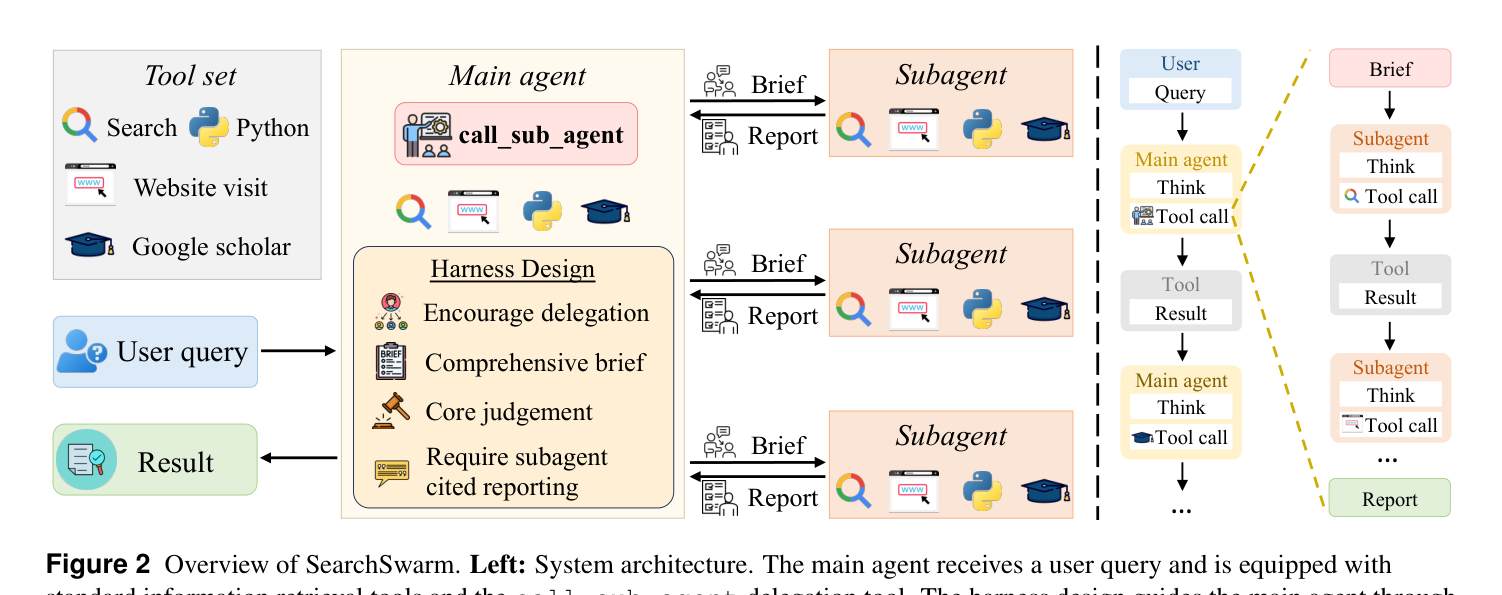
1. Harness 설계 (추론 시)
SearchSwarm은 “메인 분배, 서브 실행” 패러다임을 위한 하네스를 설계했습니다:
- 작업 분해(Task Decomposition): 메인 에이전트가 전체 과제를 독립적이고 경계가 명확한 하위 작업으로 분할
- 하위 에이전트 브리핑(Subagent Briefing): 각 서브에이전트에게 충분한 컨텍스트와 명확한 목표를 제공
- 인용 기반 결과 통합(Citation-Grounded Integration): 서브에이전트의 결과를 근거 기반으로 취합
2. SFT 데이터 합성 (훈련 시)
하네스가 생성한 궤적(trajectory)을 감독 학습 데이터로 활용:
- 하네스가 올바른 위임 결정을 포함한 궤적 생성
- 이를 SFT 데이터로 변환하여 위임 행동을 모델 가중치에 내재화
- 결과적으로 추론 시 하네스 없이도 위임 능력 발휘
3. 아키텍처
주요 성과
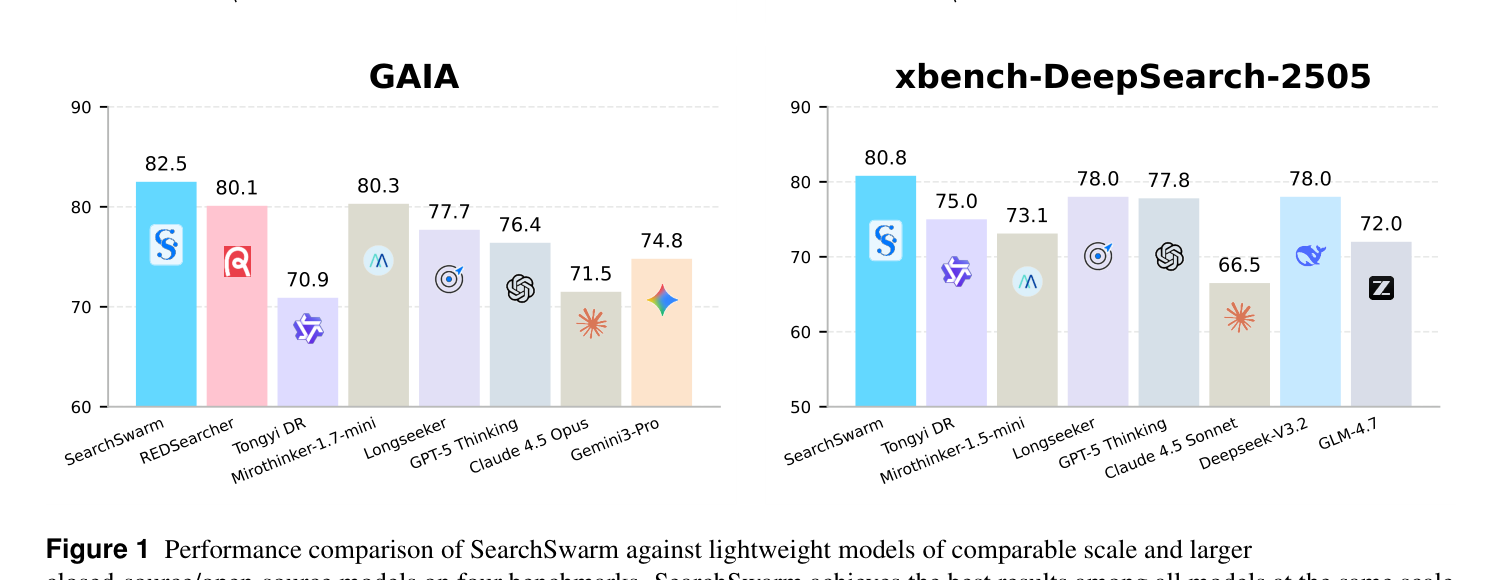
SearchSwarm-30B-A3B (30B 파라미터, 3B 활성)의 벤치마크 결과:
| 벤치마크 | 점수 |
|---|---|
| BrowseComp | 68.1 |
| BrowseComp-ZH | 73.3 |
| GAIA | 82.5 |
| xbench-DeepSearch | 80.8 |
- 동급 규모 모델 중 최고 성능
- 기반 모델 대비 평균 +14.2점 향상
- 10배 이상 큰 클로즈드 소스 모델들과 경쟁
- OpenAI DeepResearch(64.9)와 맞먹는 수준
특히 ScholarQA-v2에서 +32.7점, ResearchQA에서 +13.5점 향상을 기록하며 다중 소스 종합 능력이 크게 개선되었습니다.
시사점
- 위임이 새로운 능력: 단순히 모델을 키우는 대신, “스스로 위임하는 능력”을 학습시키는 것이 효율적
- 컨텍스트 관리의 진화: 위임은 능동적 컨텍스트 관리 — 단일 모델이 자신의 컨텍스트 한계를 넘어설 수 있게 함
- 오픈소스의 가능성: 합성 데이터로 위임 지능을 학습시키는 방법론이 오픈소스 커뮤니티에 새로운 방향 제시
- 범용성: 딥 리서치뿐 아니라 모든 장기 호라이즌 에이전트 과제에 적용 가능
한계 및 향후 방향
- 초기 탐색 단계: “예비적 탐색(preliminary exploration)“으로, 위임 지능의 전체 스펙트럼을 다루지는 않음
- 하위 작업 독립성 전제: 작업 간 깊은 의존성이 있는 경우 한계
- 합성 데이터 품질: 하네스 품질이 곧 모델 성능의 상한선