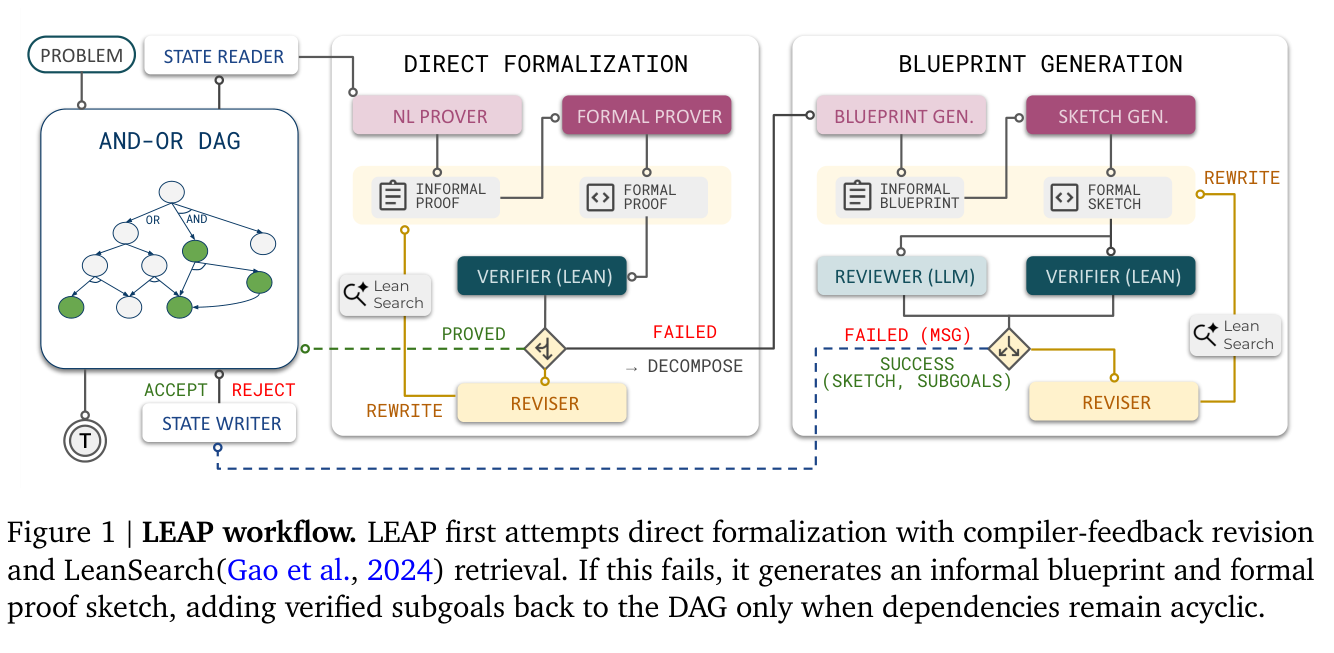
한눈에 보는 요약
Google 연구팀이 발표한 **LEAP(LLM-in-Lean Environment Agentic Prover)**은 범용 LLM을 에이전트 프레임워크로 구동해 **정형 수학 증명(formal theorem proving)**에서 최고 수준(State-of-the-Art) 성능을 달성한 연구입니다. 전문 미세조정 모델 없이도 기존 IMO 금메달 수준 시스템을 뛰어넘는 결과를 보여줍니다.
배경: LLM은 수학을 잘하지만, “증명”은 어렵다
LLM은 비형식적(informal) 수학 추론에서 강력한 성능을 보여주지만, Lean과 같은 정형 언어로 기계적으로 검증 가능한 증명을 생성하는 데는 큰 어려움이 있었습니다. 정형 증명은 컴파일러의 엄격한 타입 검사를 통과해야 하기 때문에, 자연어 수학 추론 능력이 곧 정형 증명 능력으로 직결되지 않습니다.
LEAP의 핵심 접근법
LEAP은 인간 수학자의 작업 흐름을 에이전트로 모델링한 것이 핵심입니다:
- 비격식 청사진(Blueprint) 작성: LLM이 먼저 자연어로 증명의 윤곽을 스케치
- DAG 기반 문제 분해: 복잡한 정리를 더 작은 하위 목표(subgoals)로 분해하여 방향성 비순환 그래프(DAG) 구성
- Lean 컴파일러와의 반복 상호작용: 컴파일러 피드백을 활용한 지속적 자기 정제(self-refinement)
- LLM 리뷰를 통한 분해 품질 관리: 비생산적인 분해를 사전에 필터링
핵심 결과
🏆 2025 Putnam 대회 전 문제 해결
북미 대학생 수학 경진대회인 Putnam Competition에서 LEAP은 12문제 모두 해결하며 최신 프론티어 정형 수학 모델의 돌파구와 동등한 성능을 달성했습니다.
📊 Lean-IMO-Bench에서 70% 해결률
연구팀이 새로 도입한 Lean-IMO-Bench 벤치마크에서:
| 시스템 | 해결률 |
|---|---|
| 범용 LLM (기준선) | < 10% |
| 전문 IMO 금메달급 시스템 | 48% |
| LEAP | 70% |

🔬 연구 수준의 활용
LEAP은 단순히 경진대회 문제를 넘어 실제 미해결 조합론 문제에도 적용되었습니다. Knuth의 짝수 차수 Cayley 그래프 해밀턴 분해에서 핵심 하위 문제에 대한 검증된 증명을 자율적으로 형식화했습니다.
왜 중요한가
- 특화된 미세조정이 필수라는 통념 타파: 범용 LLM만으로도 에이전트 설계를 통해 전문 시스템을 능가할 수 있음을 입증
- 에이전트 설계의 힘: 동일한 모델이라도 워크플로우를 어떻게 구조화하느냐에 따라 10% 미만에서 70%까지 성능이 도약
- 새로운 벤치마크 제공: Lean-IMO-Bench는 기존 벤치마크의 포화 상태를 넘어 더 도전적인 평가 기준 제공
한계 및 향후 방향
- LLM 리뷰 없이 자동 분해할 경우 비생산적 분해가 발생할 수 있음
- 벤치마크 성능과 실제 수학 연구 활용 사이의 갭은 여전히 존재
- 더 복잡한 연구 수준 문제로의 확장이 필요
참고
- 논문: LEAP: Supercharging LLMs for Formal Mathematics with Agentic Frameworks (arXiv 2606.03303)
- 저자: Po-Nien Kung, Linfeng Song, Dawsen Hwang, Jinsung Yoon, Chun-Liang Li, Simone Severini, Mirek Olšák, Edward Lockhart, Quoc V. Le, Burak Gokturk, Thang Luong, Tomas Pfister, Nanyun Peng
- 소속: Google