로봇이나 자율주행차가 3차원 공간을 이해하려면 “공간 기반 모델(Spatial Foundation Model)“이 필수입니다. 근데 이 모델들이 진짜로 공간을 잘 이해하고 있을까요? 19개 데이터셋, 546개 장면, 41개 모델을 전방위로 테스트한 SpatialBench 논문이 그 답을 찾았습니다. 결론부터 말하면 — 아직 멀었습니다.
SpatialBench가 뭔가요? 왜 필요한 거죠?
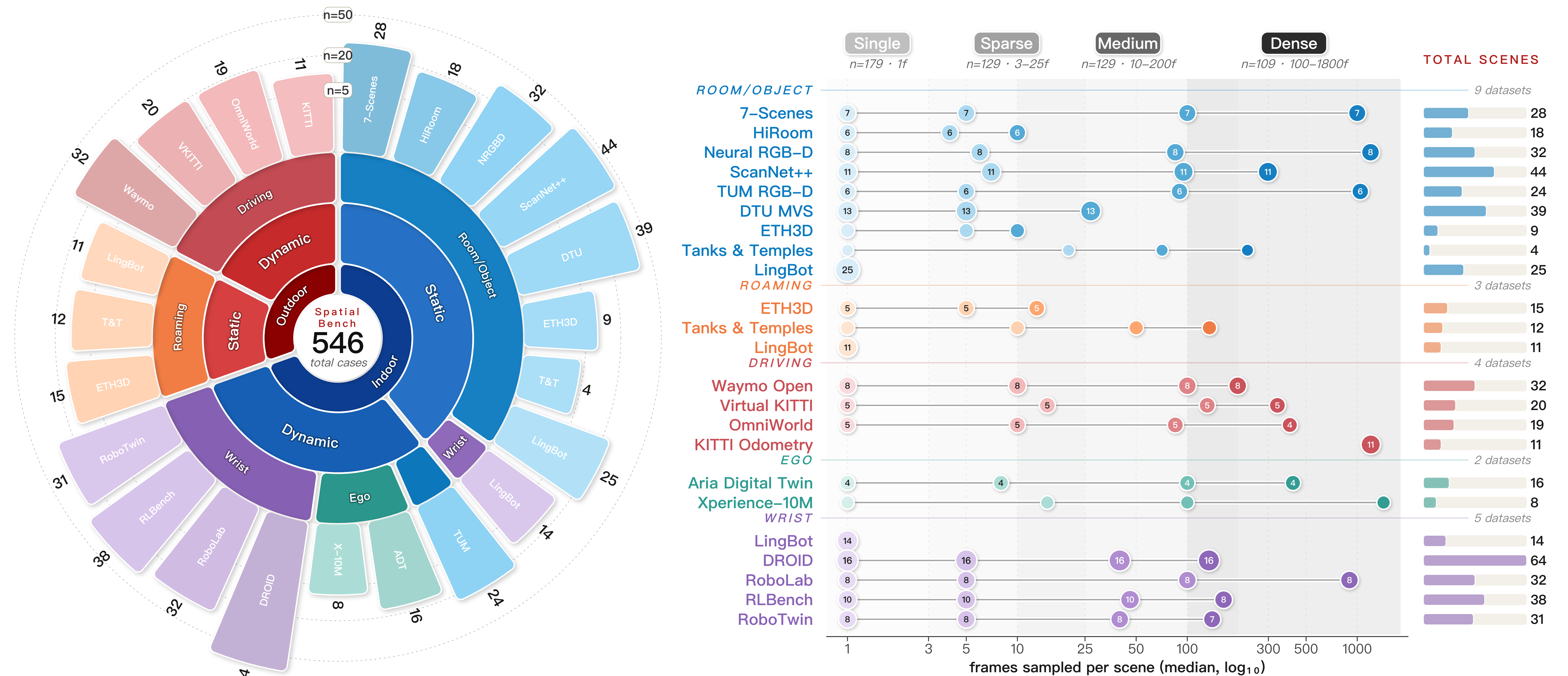
공간 기반 모델은 깊이 추정(depth estimation), 3D 재구성 같은 작업을 수행하는 모델입니다. 문제는 평가가 제각각이었다는 거예요. 연구팀마다 자기들 데이터셋에 맞춰 평가하니까, “이 모델이 진짜 좋은 건지 아니면 그 데이터셋에서만 좋은 건지” 알 수가 없었어요.
SpatialBench는 이걸 통일했습니다. 5개의 서로 다른 공간 도메인(실내·실외·항공·에고센트릭·임바디드)에서, 4가지 입력 밀도(single/sparse/medium/dense)로, 6가지 재구성 패러다임을 체계적으로 평가하는 프레임워크입니다.
41개 모델 테스트… 결과가 어떻게 나왔나요?
가장 핵심적인 발견은 **“만능 선수(all-round player)가 없다”**는 겁니다. 실내에서 잘하는 모델이 항공 데이터에서는 처참하게 무너지고, sparse 입력에 강한 모델이 dense 환경에서는 오히려 성능이 떨어지는 패턴이 반복됐습니다.
특히 에고센트릭(1인칭 영상)이나 임바디드(로봇 시점) 데이터에서는 거의 모든 모델이 고전했어요. 학습 도메인과 다른 환경에 노출되면 성능 급락이 일어나는 거죠.

DA-Next-5M 데이터셋이 뭐가 다른가요?
이 논문은 벤치마크만 만든 게 아닙니다. DA-Next-5M이라는 550만 장의 고품질 에고센트릭 프레임 데이터셋도 함께 공개했어요. 기존 데이터셋들이 주로 실내·실외 정적 장면에 치우쳐 있던 걸 보완하기 위해서죠.
여기에 DA-Next라는 베이스라인 모델도 제안했습니다. 이 모델은 메트릭 스케일(절대 거리)을 포착할 수 있도록 설계되었고, sparse 입력에서 기존 대비 47% 오류 감소를 달성했습니다.
”풀 컨텍스트 어텐션”이 정답이라는데… 비용은 어떻고요?
논문의 또 다른 핵심 발견은 어텐션 메커니즘에 관한 것입니다. 전체 컨텍스트를 한 번에 보는 **풀 컨텍스트 어텐션(full-context attention)**이 정확도 상한선을 정한다는 걸 실험적으로 보여줬어요. 하지만 이건 GPU 메모리가 충분할 때의 이야기입니다.
메모리 제약이 있을 때는 바운디드 메모리 전략(bounded-memory strategy)으로 긴 시퀀스를 처리하면서도 준수한 성능을 유지할 수 있다는 것도 확인했습니다. 실제 배포에서는 이 트레이드오프가 핵심이 되겠죠.
그래서 로봇이나 자율주행에는 어떤 의미인가요?
지금 당장 로봇에 공간 기반 모델을 탑재하려면, 작동 환경과 비슷한 도메인에서 학습된 모델을 골라야 합니다. “아무거나 좋은 거” 골라서는 안 된다는 거죠.
SpatialBench가 보여준 건, 공간 지능 분야가 아직 도메인 특화(domain-specific) 단계를 벗어나지 못했다는 사실입니다. 진정한 의미의 “기반 모델(foundation model)“이 되려면, 어떤 환경에서도 일정 수준 이상의 성능을 보장하는 범용성이 필요합니다. DA-Next와 SpatialBench는 그 방향으로 나아가는 중요한 이정표가 될 것입니다.
참고 논문: Haosong Peng et al., “SpatialBench: Is Your Spatial Foundation Model an All-Round Player?”, arXiv:2605.27367, May 2026.