“빨간색 컵이 어디 있어?” 이 질문에 이미지에서 해당 위치를 박스로 표시하는 기술을 비전-언어 그라운딩(visual grounding)이라고 합니다. NVIDIA 연구진이 발표한 LocateAnything은 기존 방식의 근본적 병목을 해결하고, 속도는 10배 빠르면서 정확도까지 높인 프레임워크입니다. 비결은 “바운딩 박스를 한 번에 병렬로 디코딩”하는 데 있었습니다.
기존 방식의 문제가 뭔가요?
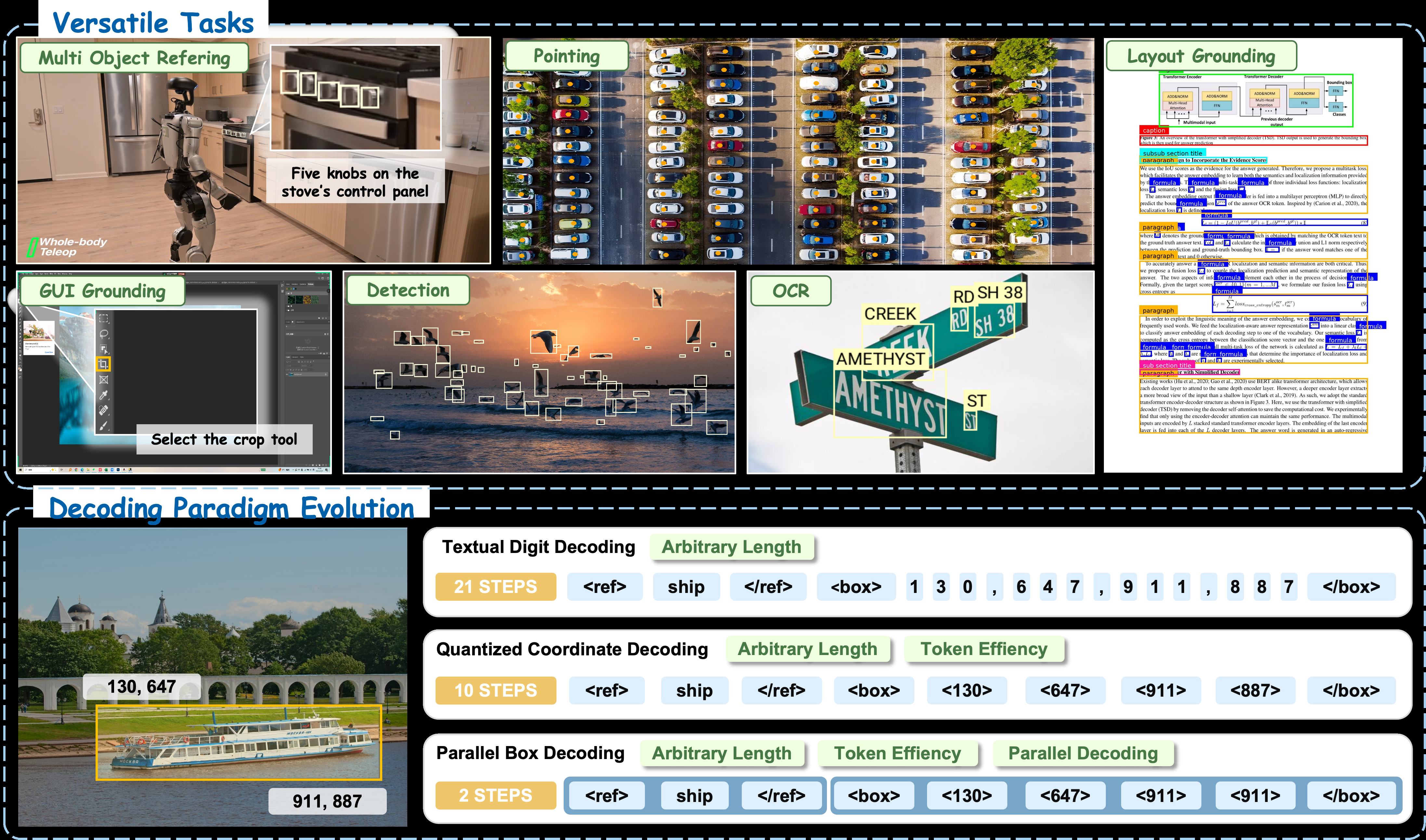
기존 비전-언어 모델들은 바운딩 박스를 토큰 시퀀스로 취급합니다. 예를 들어 [x1, y1, x2, y2] 좌표를 순차적으로 하나씩 생성하는 거죠. 이 방식은 간단하지만 두 가지 근본적 한계가 있어요.
첫째, 속도입니다. 박스 하나당 여러 토큰을 순차 생성해야 하니, 이미지에 물체가 많을수록 기하급수적으로 느려집니다. 둘째, 일관성입니다. x1을 생성한 시점과 x2를 생성한 시점의 모델 상태가 달라서, 박스 내부의 기하학적 일관성이 깨질 수 있어요.
Parallel Box Decoding이 뭔가요?
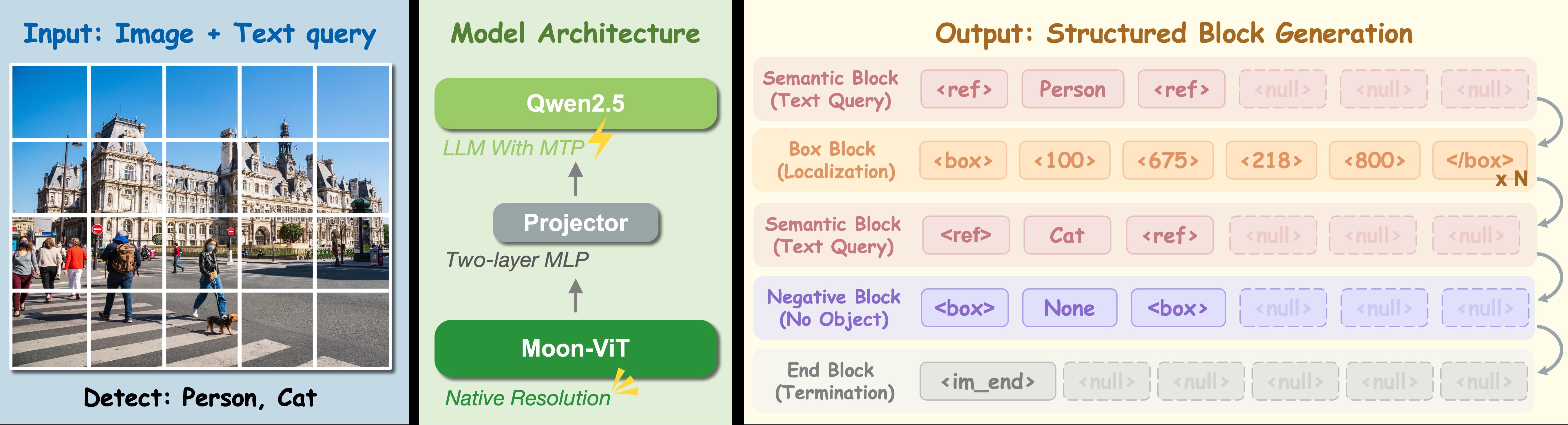
LocateAnything의 핵심 아이디어인 PBD(Parallel Box Decoding)는 바운딩 박스를 “원자 단위(atomic unit)“로 취급합니다. 박스의 네 좌표를 따로따로 생성하지 않고, 하나의 스텝에서 전체 박스를 병렬로 생성하는 거죠.
이게 가능한 이유는, 박스가 본질적으로 공간적(spatial) 객체이지 언어적 순서 객체가 아니기 때문입니다. 텍스트는 단어 순서가 의미를 갖지만, 바운딩 박스의 좌표 사이에는 “순서”보다 “공간적 관계”가 중요합니다. PBD는 이 본질을 아키텍처에 반영한 셈이죠.
10배 빠르다는 게 실제로 확인된 건가요?
네, 실험 결과가 인상적입니다. 기존 순차 디코딩 방식 대비 디코딩 처리량(throughput)에서 압도적 우위를 보여줍니다. 특히 물체 수가 많은 장면에서 그 차이가 더 벌어집니다.
게다가 속도만 빠른 게 아니라 정확도도 향상됐습니다. 박스 내부 기하학적 일관성이 보존되니까, 위치 추정 품질까지 좋아지는 부가 효과를 얻었어요. 보통은 속도-정확도 트레이드오프인데, 이건 둘 다 잡은 셈이죠.
LocateAnything-3B 모델도 공개됐다면서요?
네, 3B(30억 파라미터) 크기의 모델이 HuggingFace에 공개되어 있습니다. 연구진은 GitHub 코드(NVlabs/Eagle)도 함께 공개했고요. 데모도 HuggingFace Spaces에서 돌려볼 수 있습니다.
3B 사이즈는 실시간 애플리케이션에 배포하기에 충분히 가벼우면서도, 성능은 대형 모델들과 견줄 만합니다. 산업 적용을 염두에 둔 선택으로 보입니다.
이게 왜 중요한 건가요? 실제 응용은?
비전-언어 그라운딩은 로봇 공학, 증강 현실(AR), 이미지 검색, 자율주행 등 수많은 분야에서 기본 기능입니다. “저기 있는 의자에 앉아” 같은 명령을 로봇이 이해하려면, 먼저 “의자”가 이미지에서 어디 있는지 정확히 파악해야 하니까요.
LocateAnything의 병렬 디코딩 방식은, 공간적 출력이 필요한 모든 비전 태스크에 적용 가능한 패러다임 전환입니다. 논문에서도 지적하듯, 같은 접근이 문서 OCR의 병렬 디코딩에도 적용되고 있어요. “태스크가 공간적일 때 순차 디코딩이 진짜 병목이다”라는 통찰이 앞으로 더 많은 분야에 영향을 줄 겁니다.
참고 논문: Shihao Wang et al., “LocateAnything: Fast and High-Quality Vision-Language Grounding with Parallel Box Decoding”, arXiv:2605.27365, May 2026.