자동회귀(Autoregressive) LLM이 아닌, Diffusion 방식의 LLM이 점점 늘어나고 있습니다. 생성 속도가 빠르고 병렬 처리가 가능하니까요. 하지만 “안전성 모니터링”은 거의 연구가 없었습니다. 옥스퍼드 대학 연구진이 발표한 D²-Monitor는 Diffusion LLM의 위험한 출력을 실시간으로 감지하는 최초의 체계적 프레임워크입니다. 핵심 개념은 “망설임(hesitation)“입니다.
Diffusion LLM이 뭔가요? 왜 안전 모니터링이 다른가요?
일반적인 LLM(GPT, Claude 등)은 토큰을 왼쪽에서 오른쪽으로 하나씩 생성합니다. 반면 Diffusion LLM은 노이즈에서 시작해 여러 스텝의 디노이징(denoising) 과정을 거쳐 텍스트를 생성합니다. 한 번에 여러 토큰을 동시에 정제하는 방식이죠.
이 차이가 안전 모니터링에 결정적입니다. 자동회귀 LLM은 각 토큰 단계에서 중간 표현(intermediate representation)이 하나뿐이지만, Diffusion LLM은 디노이징 스텝마다 중간 표현이 노출됩니다. 이게 새로운 모니터링 기회를 제공합니다.
”망설임”이 뭔가요? AI가 망설인다고요?
재미있는 발견입니다. Diffusion LLM이 안전하지 않은 입력을 처리할 때, 디노이징 과정에서 특이한 패턴이 나타납니다. 모델이 특정 스텝에서 “갈팡질팡”하는 거죠. 연구진은 이걸 **“망설임(hesitation)“**이라고 정의했습니다.
쉽게 말해, 안전한 질문에는 디노이징이 순조롭게 진행되는데, 위험한 질문에는 중간에 멈칫거리는 구간이 생깁니다. 이 망설임의 정도(스텝 수)를 측정하면, 모델이 “이건 좀 애매하다”고 느끼는지 감지할 수 있습니다.
D²-Monitor는 어떻게 동작하나요?
2단계 라우팅 구조입니다:
- 기초 프로브(Base Probe): 가벼운 선형 프로브가 항상 작동하면서 안전성 분류와 동시에 망설임 점수를 계산합니다.
- 고급 프로브(Advanced Probe): 망설임 점수가 임계값을 넘으면, 더 표현력이 좋지만 무거운 프로브가 2차 분류를 수행합니다.
핵심은 동적 자원 할당입니다. 쉬운 샘플은 가벼운 프로브만으로 충분하고, 어려운 샘플만 무거운 프로브까지 동원합니다. 자원이 제한된 환경에서 특히 유리한 구조예요.
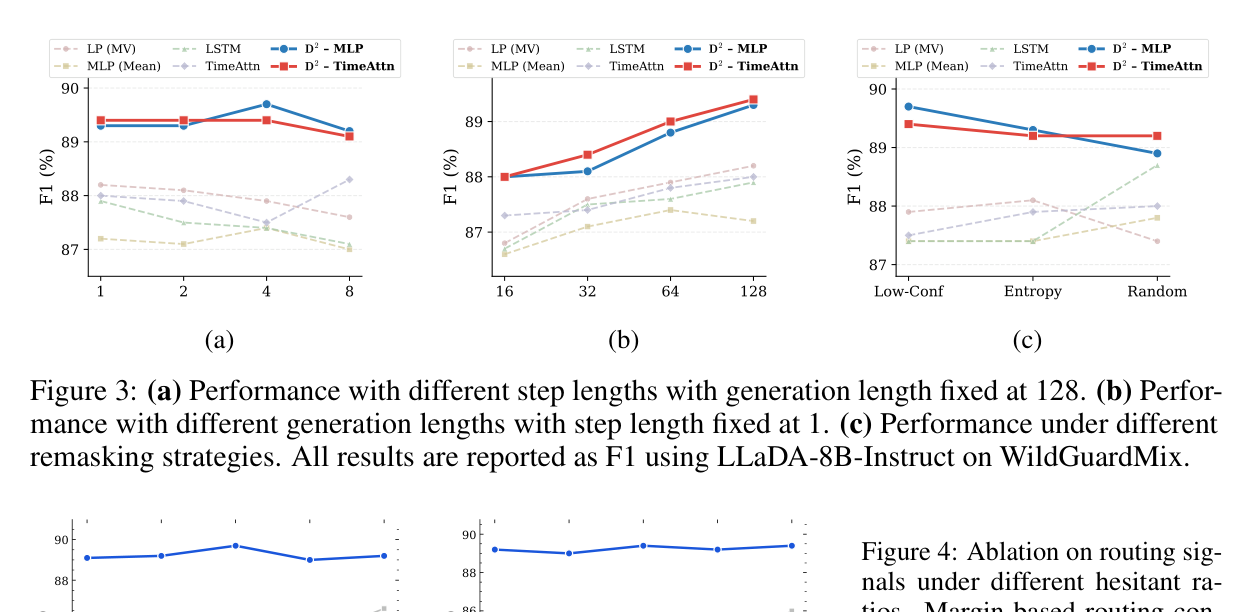
실험 결과는 어땠나요?
3개 안전 데이터셋, 4개 Diffusion LLM에서 포괄적 평가를 진행했습니다. 8개 베이스라인과 비교했고요.
결과는 인상적이었습니다. 데이터셋 내 검출(intra-dataset)과 교차 데이터셋 일반화(cross-dataset generalization) 모두에서 최고 성능을 달성했고, 효율성과 효과성의 균형에서도 최적의 트레이드오프를 보였습니다.
특히 주목할 점은 교차 데이터셋 일반화입니다. 망설임이 모델 고유의 불확실성을 반영하기 때문에, 특정 데이터셋에 과적합되지 않는다는 거죠. 이건 실제 배포 환경에서 매우 중요한 특성입니다.
이게 AI 안전에 어떤 의미를 갖나요?
Diffusion LLM이 상용화되면서 안전 모니터링의 필요성이 커지고 있습니다. D²-Monitor는:
- 실시간 모니터링: 생성 과정 중간에 개입 가능
- 경량 배포: 2단계 라우팅으로 자원 효율적
- 범용성: 망설임은 데이터셋에 독립적인 신호
라는 세 가지 강점을 갖습니다. 자동회귀 LLM의 안전 연구가 이미 활발한 반면, Diffusion LLM 안전은 거의 미개척 분야입니다. D²-Monitor는 그 시작점으로서 의미가 큽니다.
앞으로 Diffusion LLM이 더 널리 쓰이면, “망설임”이라는 개념이 안전 AI 시스템의 표준 구성 요소가 될 가능성도 있습니다. 모델이 불확실할 때 스스로 브레이크를 걸 수 있다면, 그건 AI 안전의 중요한 진전이 될 겁니다.
참고 논문: Aoxi Liu et al., “D²-Monitor: Dynamic Safety Monitoring for Diffusion LLMs via Hesitation-Aware Routing”, arXiv:2605.25893, May 2026.